
Mare Liberum

Anatomia di un Sistema di IA
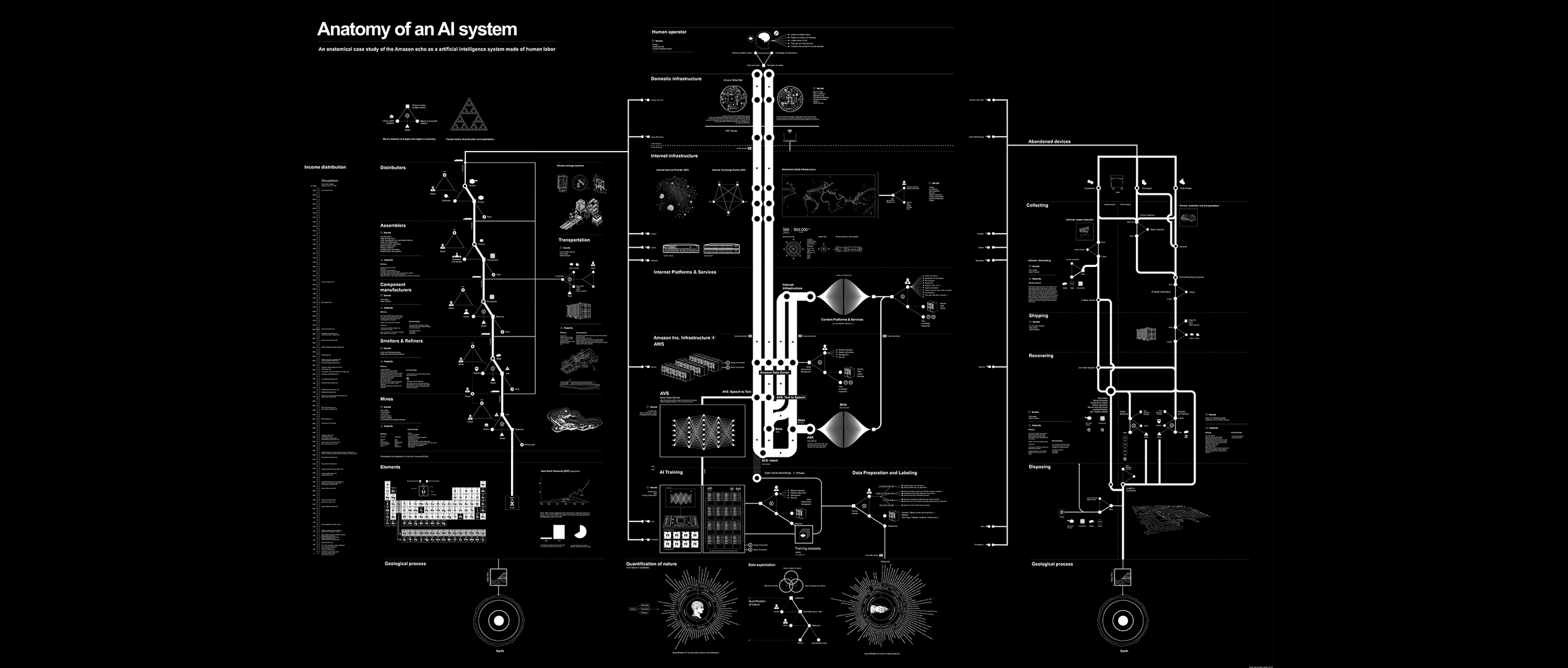 Per vedere la mappa in scala reale o scaricarla in formato pdf, vai qui: map
Per vedere la mappa in scala reale o scaricarla in formato pdf, vai qui: map
Anatomia di
un Sistema di IA
Amazon Echo come mappa anatomica del lavoro umano, dei dati e delle risorse del pianeta
Di Kate Crawford [^ 1] and Vladan Joler[ ]^ 2] (2018)

▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
I
Un cilindro si trova in una stanza. È impassibile, liscio, semplice e piccolo. È alto 14,8 cm, con un’unica luce circolare blu-verde che si sviluppa intorno al bordo superiore. Assiste in silenzio. Una donna entra nella stanza, con un bambino addormentato in braccio, e si rivolge al cilindro.
Alexa, accendi le luci della sala”.
Il cilindro prende vita. OK. La stanza si illumina. La donna fa un lieve cenno di assenso e porta il bambino al piano di sopra.
Questa è un’interazione con il dispositivo Echo di Amazon. 3 Un breve comando e una risposta sono la forma più comune di coinvolgimento con questo dispositivo di intelligenza artificiale abilitato per i consumatori. Ma in questo fugace momento di interazione, viene invocata una vasta matrice di capacità: catene intrecciate di estrazione di risorse, lavoro umano ed elaborazione algoritmica attraverso reti di estrazione, logistica, distribuzione, previsione e ottimizzazione. La scala di questo sistema è quasi al di là dell’immaginazione umana. Come possiamo iniziare a vederlo, a coglierne l’immensità e la complessità come forma connessa? Iniziamo con uno schema: una vista esplosa di un sistema planetario attraverso tre fasi di nascita, vita e morte, accompagnata da un saggio in 21 parti. L’insieme diventa una mappa anatomica di un singolo sistema di intelligenza artificiale.
Amazon Echo Dot (schemi)
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬I
II
La scena della donna che parla con Alexa è tratta da un video promozionale del 2017 che pubblicizza l’ultima versione di Amazon Echo. Il video inizia con “Saluta il nuovissimo Echo” e spiega che l’Echo si connetterà ad Alexa (l’agente intelligente o agente razionale) per “riprodurre musica, chiamare amici e famigliari, controllare dispositivi domestici intelligenti (smart) e molto altro”. Il dispositivo contiene sette microfoni direzionali, in modo che l’utente possa essere ascoltato in ogni momento anche durante la riproduzione di musica. Il dispositivo è disponibile in diversi stili, come il grigio scuro metallizzato o il beige di base, progettati per “mimetizzarsi o distinguersi”. Ma anche le opzioni di design più brillanti mantengono una sorta di bianco: nulla avverte il proprietario della vasta rete che sottende e guida le sue capacità interattive. Il video promozionale afferma semplicemente che la gamma di cose che si possono chiedere ad Alexa è in continua espansione. “Poiché Alexa è nel cloud, diventa sempre più intelligente e aggiunge nuove funzioni”.
Come avviene questo? Alexa è una voce disincarnata che rappresenta l’interfaccia di interazione essere umano-IA per una serie straordinariamente complessa di livelli di elaborazione delle informazioni. Questi livelli sono alimentati da maree costanti: il flusso di voci umane che vengono tradotte in domande testuali, utilizzate per interrogare database di potenziali risposte, e il corrispondente flusso di risposte di Alexa. Per ogni risposta fornita da Alexa, la sua efficacia viene dedotta da ciò che accade successivamente:
Viene riproposta la stessa domanda? (L’utente si è sentito ascoltato?)
La domanda è stata riformulata? (L’utente ha avuto la sensazione che la domanda fosse stata compresa?).
C’è stata un’azione dopo la domanda? (L’interazione ha portato a una risposta tracciata: una luce accesa, un prodotto acquistato, un brano riprodotto).
Con ogni interazione, Alexa si allena a sentire meglio, a interpretare in modo più preciso, a innescare azioni che corrispondono più accuratamente ai comandi dell’utente e a costruire un modello più completo delle sue preferenze, abitudini e desideri. Cosa è necessario per rendere tutto ciò possibile? In parole povere: ogni piccola comodità – che si tratti di rispondere a una domanda, accendere una luce o suonare una canzone – richiede una vasta rete planetaria, alimentata dall’estrazione di materie non-rinnovabili, manodopera e dati. L’entità delle risorse richieste è di gran lunga superiore all’energia e alla manodopera necessarie a un essere umano per far funzionare un elettrodomestico o premere un interruttore. Una contabilità completa di questi costi è quasi impossibile, ma è sempre più importante coglierne l’entità e la portata se vogliamo comprendere e governare le infrastrutture tecniche che attraversano le nostre vite.
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
III
Il Salar, la più grande superficie pianeggiante del mondo, si trova nel sud-ovest della Bolivia, a un’altitudine di 3.656 metri sul livello del mare. Si tratta di un altopiano ricoperto da pochi metri di crosta salina eccezionalmente ricca di litio, che contiene il 50%-70% delle riserve mondiali di litio. 4 Il Salar, insieme alle vicine regioni di Atacama in Cile e Argentina, sono i principali siti di estrazione del litio. Questo metallo morbido e argenteo viene attualmente utilizzato per alimentare i dispositivi mobili connessi, come materiale fondamentale per la produzione di batterie agli ioni di litio. È noto come “oro grigio”. Le batterie degli smartphone, ad esempio, contengono solitamente meno di otto grammi di questo materiale. 5 Ogni auto Tesla ha bisogno di circa sette chilogrammi di litio per il suo pacco batterie. 6 Tutte queste batterie hanno una durata limitata e una volta consumate vengono gettate via come rifiuti. Amazon ricorda agli utenti che non è possibile aprire e riparare il proprio Echo, perché questo invalida la garanzia. Amazon Echo è alimentato a parete e dispone anche di una batteria mobile. Anche questa ha una durata limitata e deve essere gettata via come rifiuto.
Secondo le leggende Aymara sulla creazione della Bolivia, le montagne vulcaniche dell’altopiano andino sono state create da una tragedia. 7 Molto tempo fa, quando i vulcani erano vivi e vagavano liberamente per le pianure, Tunupa – l’unico vulcano femmina – diede alla luce un bambino. Colpiti dalla gelosia, i vulcani maschi le rubarono il bambino e lo bandirono in un luogo lontano. Gli dei punirono i vulcani immobilizzandoli tutti sulla Terra. Addolorata per il bambino che non poteva più raggiungere, Tunupa pianse profondamente. Le sue lacrime e il latte materno si unirono per creare un gigantesco lago salato: Salar de Uyuni. Come osservano Liam Young e Kate Davies, “il vostro smartphone funziona con le lacrime e il latte materno di un vulcano”. Questo paesaggio è collegato a qualsiasi luogo del pianeta attraverso i telefoni che abbiamo in tasca; è legato a ciascuno di noi da fili invisibili di commercio, scienza, politica e potere”. 8

▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
IV
Il nostro diagramma esploso accosta e visualizza tre processi centrali ed estrattivi necessari per far funzionare un sistema di intelligenza artificiale su larga scala: risorse materiali, lavoro umano e dati. Consideriamo questi tre elementi nel tempo, rappresentati come una descrizione visiva della nascita, della vita e della morte di una singola unità Amazon Echo. È necessario andare oltre la semplice analisi del rapporto tra un singolo essere umano, i suoi dati e una singola azienda tecnologica per affrontare la scala veramente planetaria dell’estrazione. Vincent Mosco ha mostrato come la metafora eterea della “nuvola” per la gestione e l’elaborazione dei dati esterni sia in completa contraddizione con la realtà fisica dell’estrazione di minerali dalla crosta terrestre e dell’espropriazione delle popolazioni umane che ne sostengono l’esistenza. 9 Sandro Mezzadra e Brett Nielson usano il termine “estrattivismo” per indicare la relazione tra le diverse forme di operazioni estrattive nel capitalismo contemporaneo, che vediamo ripetersi nel contesto dell’industria dell’IA. 10 Esistono profonde interconnessioni tra il letterale svuotamento dei materiali della terra e della biosfera e la cattura dei dati e la monetizzazione delle pratiche umane di comunicazione e socialità nell’IA. Mezzadra e Nielson notano che il lavoro è al centro di questa relazione estrattiva, che si è ripetuta nel corso della storia: dal modo in cui l’imperialismo europeo ha utilizzato il lavoro degli schiavi, alle squadre di lavoro forzato nelle piantagioni di caucciù in Malesia, alle popolazioni indigene della Bolivia spinte a estrarre l’argento che è stato utilizzato nella prima moneta globale. Pensare all’estrazione richiede di pensare al lavoro, alle risorse e ai dati insieme. Ciò rappresenta una sfida per la comprensione critica e popolare dell’intelligenza artificiale: è difficile “vedere” uno qualsiasi di questi processi singolarmente, per non parlare di quelli collettivi. Da qui la necessità di una visualizzazione in grado di riunire in un’unica mappa questi processi collegati ma dispersi a livello globale.

▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
V
Se si legge la nostra mappa da sinistra a destra, la storia inizia e finisce con la Terra e i processi geologici del tempo profondo. Ma se la leggiamo dall’alto verso il basso, vediamo la storia che inizia e finisce con un essere umano. In alto c’è l’agente umano che interroga l’Echo e fornisce ad Amazon i preziosi dati di addestramento delle domande e delle risposte verbali che può utilizzare per perfezionare ulteriormente i suoi sistemi di intelligenza artificiale abilitati alla voce. Nella parte inferiore della mappa si trova un altro tipo di risorsa umana: la storia della conoscenza e della capacità umana, che viene utilizzata anche per addestrare e ottimizzare i sistemi di intelligenza artificiale. Questa è una differenza fondamentale tra i sistemi di intelligenza artificiale e altre forme di tecnologia di consumo: si basano sull’ingestione, l’analisi e l’ottimizzazione di grandi quantità di immagini, testi e video generati dall’uomo.

▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
VI
Quando un essere umano interagisce con un Echo o con un altro dispositivo di intelligenza artificiale abilitato alla riproduzione vocale, agisce come molto più di un semplice consumatore di prodotti finali. È difficile collocare l’utente umano di un sistema di IA in un’unica categoria: merita piuttosto di essere considerato come un caso ibrido. Così come la chimera greca era un animale mitologico in parte leone, in parte capra, in parte serpente e in parte mostro, l’utente di Echo è contemporaneamente un consumatore, una risorsa, un lavoratore e un prodotto. Questa identità multipla ricorre per gli utenti umani in molti sistemi tecnologici. Nel caso specifico di Amazon Echo, l’utente ha acquistato un dispositivo di consumo per il quale riceve una serie di comodi vantaggi. Ma è anche una risorsa, poiché i suoi comandi vocali vengono raccolti, analizzati e conservati per costruire un corpus sempre più ampio di voci e istruzioni umane. Forniscono anche avoro, in quanto svolgono continuamente il prezioso servizio di contribuire ai meccanismi di feedback relativi all’accuratezza, all’utilità e alla qualità complessiva delle risposte di Alexa. In sostanza, contribuiscono ad addestrare le reti neurali all’interno dello stack infrastrutturale di Amazon.
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
VII
Tutto ciò che va oltre le limitate interfacce fisiche e digitali del dispositivo stesso è fuori dal controllo dell’utente. Il dispositivo si presenta come una superficie elegante, senza la possibilità di aprirlo, ripararlo o modificarne il funzionamento. L’oggetto in sé è una semplicissima estrusione di plastica che rappresenta un insieme di sensori: la sua vera potenza e complessità si trova altrove, lontano dalla vista. L’Echo non è altro che un “orecchio” in casa: un agente di ascolto disincarnato che non mostra mai le sue profonde connessioni con i sistemi remoti.
Nel 1673, il polimatico gesuita Athanasius Kircher inventò la statua citofonica, la “statua parlante”. Kircher fu uno straordinario studioso e inventore interdisciplinare. Nella sua vita pubblicò quaranta opere importanti nei campi della medicina, della geologia, della religione comparata e della musica. Inventò il primo orologio magnetico, molti dei primi automi e il megafono. La sua statua parlante era un sistema di ascolto molto precoce: essenzialmente un microfono ricavato da un enorme tubo a spirale, che poteva trasmettere le conversazioni da una piazza pubblica e salire attraverso il tubo, per poi passare attraverso la bocca di una statua conservata nelle stanze private di un aristocratico. Come scrisse Kircher:
“Questa statua deve essere collocata in un determinato luogo, in modo che la sezione finale del tubo a spirale corrisponda esattamente all’apertura della bocca. In questo modo sarà perfetta, e in grado di emettere chiaramente qualsiasi tipo di suono: infatti la statua sarà in grado di parlare continuamente, pronunciando una voce umana o animale: riderà o sogghignerà; sembrerà piangere o gemere davvero; a volte con grande stupore soffierà con forza. Se l’apertura del tubo a forma di spirale si trova in corrispondenza di uno spazio pubblico aperto, tutte le parole umane pronunciate, concentrate nel condotto, verrebbero riprodotte attraverso la bocca della statua”. 11
Il sistema di ascolto poteva origliare le conversazioni quotidiane della piazza e trasmetterle agli oligarchi italiani del XVII secolo. La statua parlante di Kircher era una prima forma di estrazione di informazioni per le élite: le persone che parlavano per strada non avevano alcuna indicazione del fatto che le loro conversazioni venissero incanalate verso coloro che avrebbero sfruttato quella conoscenza per il proprio potere, intrattenimento e ricchezza. Le persone all’interno delle case degli aristocratici non avrebbero avuto idea di come una statua magica parlasse e trasmettesse ogni sorta di informazione. L’obiettivo era quello di oscurare il funzionamento del sistema: una statua elegante era tutto ciò che potevano vedere. I sistemi di ascolto, anche in questa fase iniziale, avevano a che fare con il potere, la classe e la segretezza. Ma l’infrastruttura del sistema di Kircher era proibitiva e disponibile solo per pochi. Rimane quindi la domanda: quali sono le implicazioni in termini di risorse per la costruzione di tali sistemi? Questo ci porta alla materialità dell’infrastruttura sottostante.
 Statua citofonica di Athanasius Kircher (1673)
Statua citofonica di Athanasius Kircher (1673)
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
VIII
Nel suo libro A Geology of Media, Jussi Parikka suggerisce di provare a pensare ai media non dal punto di vista di Marshall McLuhan – in cui i media sono estensioni dei sensi umani 12 – ma piuttosto come un’estensione della Terra. 13 Le tecnologie dei media dovrebbero essere comprese nel contesto di un processo geologico, dalla creazione e dai processi di trasformazione, al movimento degli elementi naturali da cui i media sono costruiti. Riflettere sui media e sulla tecnologia come processi geologici ci permette di considerare il profondo esaurimento delle risorse non rinnovabili necessarie per alimentare le tecnologie del momento. Ogni oggetto della rete estesa di un sistema di intelligenza artificiale, dai router di rete alle batterie ai microfoni, è costruito utilizzando elementi che hanno richiesto miliardi di anni per essere prodotti. Guardando dalla prospettiva del tempo profondo, stiamo estraendo la storia della Terra per servire una frazione di secondo di tempo tecnologico, al fine di costruire dispositivi che spesso sono progettati per essere utilizzati per non più di qualche anno. Ad esempio, la Consumer Technology Association rileva che la vita media degli smartphone è di 4,7 anni. 14 Questo ciclo di obsolescenza alimenta l’acquisto di un maggior numero di dispositivi, fa aumentare i profitti e incentiva l’uso di pratiche di estrazione non sostenibili. Da un lento processo di sviluppo degli elementi, questi elementi e materiali attraversano un periodo straordinariamente rapido di scavo, fusione, miscelazione e trasporto logistico – attraversando migliaia di chilometri nella loro trasformazione. I processi geologici segnano sia l’inizio che la fine di questo periodo, dall’estrazione del minerale al deposito del materiale in una discarica elettronica. Per questo motivo, la nostra mappa inizia e finisce con la crosta terrestre. Tuttavia, tutte le trasformazioni e i movimenti che raffiguriamo sono solo un abbozzo anatomico: al di sotto di queste connessioni si trovano molti altri strati di catene di approvvigionamento frattali, sfruttamento delle risorse umane e naturali, concentrazioni di potere aziendale e geopolitico e consumo continuo di energia.
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
IX
Tracciare le connessioni tra risorse, lavoro ed estrazione di dati ci riporta inevitabilmente ai quadri tradizionali di sfruttamento. Ma come viene generato il valore attraverso questi sistemi? Un utile strumento concettuale si trova nel lavoro di Christian Fuchs e di altri autori che esaminano e definiscono il lavoro digitale. Il concetto di lavoro digitale, inizialmente collegato a diverse forme di lavoro non materiale, precede la vita di dispositivi e sistemi complessi come l’intelligenza artificiale. Il lavoro digitale – il lavoro di costruzione e manutenzione dello stack di sistemi digitali – è tutt’altro che effimero o virtuale, ma è profondamente incarnato in diverse attività. 15 La portata è enorme: dal lavoro di migranti nelle miniere per l’estrazione dei minerali che costituiscono la base fisica delle tecnologie dell’informazione, al lavoro dei processi di produzione e assemblaggio dell’hardware, rigorosamente controllati e talvolta pericolosi, nelle fabbriche cinesi, ai lavoratori cognitivi sfruttati in outsourcing nei Paesi in via di sviluppo che etichettano le serie di dati di addestramento dell’intelligenza artificiale, fino ai lavoratori fisici informali che ripuliscono le discariche di rifiuti tossici. Questi processi creano nuovi accumuli di ricchezza e potere, che si concentrano in uno strato sociale molto sottile.
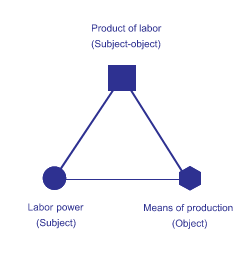 La dialettica di Marx tra soggetto e oggetto in economia.
La dialettica di Marx tra soggetto e oggetto in economia.
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
X
Questo triangolo di estrazione e produzione di valore rappresenta uno degli elementi fondamentali della nostra mappa, dalla nascita in un processo geologico, attraverso la vita come prodotto di consumo dell’intelligenza artificiale, fino alla morte in una discarica di rifiuti elettronici. Come nell’opera di Fuchs, i nostri triangoli non sono isolati, ma collegati tra loro nel processo di produzione. Formano un flusso ciclico in cui il prodotto del lavoro si trasforma in una risorsa, che si trasforma in un prodotto, che si trasforma in una risorsa e così via. Ogni triangolo rappresenta una fase del processo produttivo. Sebbene questo appaia sulla mappa come un percorso lineare di trasformazione, una metafora visiva diversa rappresenta meglio la complessità dell’estrattivismo attuale: la struttura frattale nota come triangolo di Sierpinski.
Una visualizzazione lineare non ci permette di mostrare che ogni fase successiva della produzione e dello sfruttamento contiene le fasi precedenti. Se guardiamo al sistema di produzione e sfruttamento attraverso una struttura visiva frattale, il triangolo più piccolo rappresenterebbe le risorse naturali e i mezzi di lavoro, cioè il minatore come lavoro e il minerale come prodotto. Il triangolo successivo, più grande, comprende la lavorazione dei metalli e quello successivo rappresenterebbe il processo di produzione dei componenti e così via. Il triangolo finale della nostra mappa, la produzione stessa dell’unità Amazon Echo, comprende tutti questi livelli di sfruttamento, dal basso fino al vertice di Amazon Inc, un ruolo abitato da Jeff Bezos in qualità di CEO di Amazon. Come un faraone dell’antico Egitto, egli si trova in cima alla più grande piramide di estrazione del valore dell’IA.
Triangolo di Sierpinski o frattale di Sierpinski
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
XI
Per tornare all’elemento di base di questa visualizzazione – una variazione del triangolo di produzione di Marx – ogni triangolo crea un surplus di valore per creare profitti. Se osserviamo la scala del reddito medio per ogni attività nel processo di produzione di un dispositivo, che è mostrata sul lato sinistro della nostra mappa, vediamo la drammatica differenza di reddito guadagnato. Secondo una ricerca di Amnesty International, durante l’estrazione del cobalto, utilizzato anche per le batterie al litio di 16 marche multinazionali, i lavoratori sono pagati l’equivalente di un dollaro USA al giorno per lavorare in condizioni pericolose per la vita e la salute, e spesso sono stati sottoposti a violenze, estorsioni e intimidazioni. 16 Amnesty ha documentato che nelle miniere lavorano bambini di soli 7 anni. Al contrario, l’amministratore delegato di Amazon Jeff Bezos, in cima alla nostra piramide frattale, ha guadagnato in media 275 milioni di dollari al giorno nei primi cinque mesi del 2018, secondo il Bloomberg Billionaires Index. 17 Un bambino che lavora in una miniera del Congo avrebbe bisogno di più di 700.000 anni di lavoro ininterrotto per guadagnare la stessa cifra di un solo giorno di reddito di Bezos.
Molti dei triangoli mostrati su questa mappa nascondono storie diverse di sfruttamento del lavoro e condizioni di lavoro disumane. Il prezzo ecologico della trasformazione degli elementi e delle disparità di reddito è solo uno dei possibili modi di rappresentare una profonda disuguaglianza sistemica. Entrambi abbiamo studiato diverse forme di “scatole nere” intese come processi algoritmici, ma questa mappa evidenzia un’altra forma di opacità: i processi stessi di creazione, formazione e funzionamento di un dispositivo come Amazon Echo sono essi stessi una sorta di scatola nera, molto difficile da esaminare e tracciare in toto dati i molteplici strati di appaltatori, distributori e partner logistici a valle in tutto il mondo. Come scrive Mark Graham, “il capitalismo contemporaneo nasconde ai consumatori le storie e le geografie della maggior parte delle merci. I consumatori sono di solito in grado di vedere le merci solo nel qui e ora del tempo e dello spazio, e raramente hanno l’opportunità di guardare indietro attraverso le catene di produzione per acquisire conoscenze sui luoghi di produzione, trasformazione e distribuzione”. 19
Un esempio della difficoltà di indagare e tracciare il processo della catena di produzione contemporanea è rappresentato dal fatto che Intel ha impiegato più di quattro anni per comprendere la sua linea di fornitura abbastanza bene da assicurarsi che nessun tantalio proveniente dal Congo fosse presente nei suoi microprocessori. In qualità di produttore di chip semiconduttori, Intel fornisce processori ad Apple. Per farlo, Intel dispone di una propria catena di approvvigionamento a più livelli, composta da oltre 19.000 fornitori in più di 100 Paesi, che forniscono materiali diretti per i processi di produzione, strumenti e macchinari per le fabbriche e servizi di logistica e imballaggio. 20 Il fatto che un’azienda leader nel settore tecnologico abbia impiegato più di quattro anni solo per comprendere la propria catena di fornitura rivela quanto questo processo possa essere difficile da comprendere dall’interno, per non parlare dei ricercatori esterni, dei giornalisti e degli accademici. Anche l’azienda tecnologica olandese Philips ha dichiarato di essere al lavoro per rendere la propria catena di approvvigionamento “priva di conflitti”. Philips, ad esempio, ha decine di migliaia di fornitori diversi, ognuno dei quali fornisce componenti diversi per i propri processi produttivi. 21 Questi fornitori sono a loro volta collegati a valle a decine di migliaia di produttori di componenti che acquistano i materiali da centinaia di raffinerie che acquistano gli ingredienti da diverse fonderie, che si riforniscono da un numero imprecisato di commercianti che hanno a che fare direttamente con operazioni di estrazione mineraria sia legali che illegali. In The Elements of Power, David S. Abraham descrive le reti invisibili dei commercianti di metalli rari nelle catene di fornitura dell’elettronica globale: “La rete per portare i metalli rari dalla miniera al vostro computer portatile viaggia attraverso una rete oscura di commercianti, trasformatori e produttori di componenti. I commercianti sono gli intermediari che non si limitano a comprare e vendere metalli rari: contribuiscono a regolare le informazioni e sono l’anello nascosto che aiuta a navigare nella rete tra le fabbriche di metalli e i componenti dei nostri computer portatili”. 22 Secondo l’azienda produttrice di computer Dell, le complessità della catena di approvvigionamento dei metalli pongono sfide quasi insormontabili. 23 L’estrazione di questi minerali avviene molto prima dell’assemblaggio del prodotto finale, rendendo estremamente difficile rintracciare l’origine dei minerali. Inoltre, molti minerali vengono fusi insieme a metalli riciclati, e a quel punto diventa praticamente impossibile risalire alla loro origine. Il tentativo di catturare l’intera catena di approvvigionamento è quindi un compito davvero gigantesco: rivela tutta la complessità della produzione globale di prodotti tecnologici del XXI secolo.
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
XII
Le catene di fornitura sono spesso stratificate l’una sull’altra, in una rete tentacolare. Il programma dei fornitori di Apple rivela che ci sono decine di migliaia di singoli componenti incorporati nei suoi dispositivi, a loro volta forniti da centinaia di aziende diverse. Affinché ciascuno di questi componenti arrivi alla catena di montaggio finale, dove sarà assemblato dagli operai degli stabilimenti Foxconn, è necessario trasferire fisicamente i diversi componenti da oltre 750 siti di fornitori in 30 Paesi diversi. 24 Si tratta di una complessa struttura di catene di fornitura all’interno di catene di fornitura, un frattale che si ingrandisce con decine di migliaia di fornitori, milioni di chilometri di materiali spediti e centinaia di migliaia di lavoratori inclusi nel processo ancor prima che il prodotto venga assemblato sulla linea.
Visualizzando questo processo come un’unica rete globale, pan-continentale, attraverso la quale scorrono materiali, componenti e prodotti, vediamo un’analogia con la rete informatica globale. Dove c’è un singolo pacchetto Internet che viaggia verso un Amazon Echo, qui possiamo immaginare un singolo container. 25 Lo spettacolo vertiginoso della logistica e della produzione globale non sarebbe stato possibile senza l’invenzione di questo semplice oggetto metallico standardizzato. I container standardizzati hanno permesso l’esplosione dell’industria navale moderna, che ha reso possibile modellare il pianeta come un’unica, enorme fabbrica. Nel 2017, la capacità delle navi portacontainer nel commercio marittimo ha raggiunto quasi 250.000.000 di tonnellate di portata lorda, dominate da gigantesche compagnie di navigazione come la danese Maersk, la svizzera Mediterranean Shipping Company e la francese CMA CGM Group, ognuna delle quali possiede centinaia di navi portacontainer. 26 Per queste imprese commerciali, il trasporto merci è un modo relativamente economico di attraversare il sistema vascolare della fabbrica globale, ma nasconde costi esterni molto più grandi.
Negli ultimi anni, le navi da trasporto producono il 3,1% delle emissioni annue globali di CO2, più dell’intera Germania. 27 Per ridurre al minimo i costi interni, la maggior parte delle compagnie di navigazione di container utilizza carburante di qualità molto bassa in quantità enormi, il che comporta un aumento delle quantità di zolfo nell’aria, oltre ad altre sostanze tossiche. È stato stimato che una sola nave portacontainer può emettere una quantità di inquinamento pari a quella di 50 milioni di automobili e che ogni anno 60.000 morti in tutto il mondo sono attribuite indirettamente a problemi di inquinamento legati all’industria delle navi da carico. 28 Anche fonti amiche dell’industria, come il World Shipping Council, ammettono che ogni anno migliaia di container vanno persi, sul fondo dell’oceano o alla deriva. 29 Alcuni trasportano sostanze tossiche che si disperdono negli oceani. In genere, i lavoratori trascorrono dai 9 ai 10 mesi in mare, spesso con lunghi turni di lavoro e senza accesso a comunicazioni esterne. I lavoratori delle Filippine rappresentano più di un terzo della forza lavoro del trasporto marittimo globale. 30 I costi più gravi della logistica globale ricadono sull’atmosfera, sull’ecosistema oceanico e su tutto ciò che contiene e sui lavoratori, i meno pagati.
 Cargo container.
Cargo container.
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
XIII
La crescente complessità e miniaturizzazione della nostra tecnologia dipende da un processo che stranamente fa risuonare le speranze dell’alchimia medievale. Mentre gli alchimisti medievali miravano a trasformare i metalli di base in metalli “nobili”, oggi i ricercatori utilizzano i metalli delle terre rare per migliorare le prestazioni di altri minerali. Esistono 17 elementi delle terre rare, che sono incorporati nei computer portatili e negli smartphone, rendendoli più piccoli e leggeri. Sono presenti nei display a colori, negli altoparlanti, negli obiettivi delle fotocamere, nei sistemi GPS, nelle batterie ricaricabili, nei dischi rigidi e in molti altri componenti. Sono elementi chiave nei sistemi di comunicazione, dai cavi in fibra ottica all’amplificazione del segnale nelle torri di comunicazione mobile, fino ai satelliti e alla tecnologia GPS. Ma la configurazione e l’uso precisi di questi minerali sono difficili da accertare. Così come gli alchimisti medievali nascondevano le loro ricerche dietro cifrari e simbolismi criptici, i processi contemporanei di utilizzo dei minerali nei dispositivi sono protetti da NDA (Non-Disclosure-Agreement) e segreti commerciali.
Le caratteristiche elettroniche, ottiche e magnetiche uniche degli elementi delle terre rare non possono essere eguagliate da nessun altro metallo o sostituto sintetico finora scoperto. Sebbene siano chiamati “metalli delle terre rare”, alcuni sono relativamente abbondanti nella crosta terrestre, ma l’estrazione è costosa e altamente inquinante. David Abraham descrive l’estrazione del disprosio e del terbio, utilizzati in una serie di dispositivi high-tech, a Jianxi, in Cina. Scrive: “Solo lo 0,2% dell’argilla estratta contiene i preziosi elementi delle terre rare. Ciò significa che il 99,8% della terra rimossa nelle miniere di terre rare viene scartata sotto forma di rifiuti chiamati “sterili” che vengono riversati nelle colline e nei corsi d’acqua”, creando nuovi inquinanti come l’ammonio. 31 Per raffinare una tonnellata di terre rare, “la Società cinese delle terre rare stima che il processo produca 75.000 litri di acqua acida e una tonnellata di residui radioattivi”. 32 Inoltre, le attività di estrazione e raffinazione consumano grandi quantità di acqua e generano grandi quantità di emissioni di CO2. Nel 2009, la Cina ha prodotto il 95% della fornitura mondiale di questi elementi e si stima che la singola miniera nota come Bayan Obo contenga il 70% delle riserve mondiali. 33
 Elementi delle terre rare
Elementi delle terre rare
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
XIV
Un’immagine satellitare della minuscola isola indonesiana di Bangka racconta il tributo umano e ambientale della produzione di semiconduttori. Su questa minuscola isola, i minatori, per lo più “informali”, si trovano su galleggianti di fortuna, usano pali di bambù per raschiare il fondale marino e poi si immergono sott’acqua per aspirare lo stagno dalla superficie attraverso tubi giganti simili al vuoto. Come riporta un’inchiesta del Guardian, “l’estrazione dello stagno è un commercio lucrativo ma distruttivo che ha sfregiato il paesaggio dell’isola, raso al suolo le sue fattorie e le sue foreste, ucciso gli stock ittici e le barriere coralline e intaccato il turismo sulle sue graziose spiagge ornate di palme”. I danni si vedono meglio dall’alto, quando sacche di foresta lussureggiante si nascondono tra enormi distese di terra arancione e brulla. Dove non è dominata dalle miniere, è costellata di tombe, molte delle quali contengono i corpi dei minatori che sono morti nel corso dei secoli scavando per lo stagno”. 34 Due piccole isole, Bangka e Belitung, producono il 90% dello stagno indonesiano e l’Indonesia è il secondo esportatore mondiale di questo metallo. La società nazionale indonesiana dello stagno, PT Timah, rifornisce direttamente aziende come Samsung e i produttori di saldature Chernan e Shenmao, che a loro volta riforniscono Sony, LG e Foxconn. 35
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
XV
Nei centri di distribuzione di Amazon, vaste collezioni di prodotti sono disposte in ordine computazionale su milioni di scaffali. La posizione di ogni articolo in questo spazio è determinata con precisione da complesse funzioni matematiche che elaborano le informazioni sugli ordini e creano relazioni tra i prodotti. L’obiettivo è ottimizzare i movimenti dei robot e degli esseri umani che collaborano in questi magazzini. Con l’aiuto di un braccialetto elettronico, il lavoratore umano viene guidato in magazzini grandi come hangar di aerei, pieni di oggetti disposti secondo un ordine algoritmico opaco. 36
Nascosto tra le migliaia di altri brevetti pubblicamente disponibili di proprietà di Amazon, il brevetto statunitense numero 9.280.157 rappresenta una straordinaria illustrazione dell’alienazione dei lavoratori, un momento cruciale nel rapporto tra uomini e macchine. 37 Il brevetto raffigura una gabbia metallica destinata al lavoratore, dotata di diversi componenti cibernetici, che può essere spostata in un magazzino dallo stesso sistema motorizzato che sposta gli scaffali pieni di merce. In questo caso, il lavoratore diventa parte di un balletto macchinico, tenuto in piedi in una gabbia che detta e vincola il suo movimento.
Come abbiamo visto più volte nella ricerca per la nostra mappa, i futuri distopici sono costruiti sui regimi distopici distribuiti in modo diseguale del passato e del presente, sparsi in una serie di catene di produzione per i moderni dispositivi tecnici. I pochi che si trovano in cima alla piramide frattale dell’estrazione di valore vivono in una straordinaria ricchezza e comodità. Ma la maggior parte delle piramidi è fatta dai tunnel bui delle miniere, dai laghi di rifiuti radioattivi, dai container navali dismessi e dai dormitori delle fabbriche aziendali.
 Brevetto Amazon numero 20150066283 A1
Brevetto Amazon numero 20150066283 A1
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
XVI
Alla fine del XIX secolo, un particolare albero del Sud-Est asiatico chiamato palaquium gutta divenne il centro di un boom tecnologico. Questi alberi, che si trovano principalmente in Malesia, producono un lattice naturale bianco lattiginoso chiamato guttaperca. Dopo che lo scienziato inglese Michael Faraday pubblicò nel 1848 uno studio sull’uso di questo materiale come isolante elettrico, la guttaperca divenne rapidamente il beniamino del mondo dell’ingegneria. Fu vista come la soluzione al problema di isolare i cavi telegrafici in modo che potessero resistere alle condizioni del fondo dell’oceano. Con la crescita dell’attività sottomarina globale, aumentò anche la domanda di tronchi di palaquium gutta. Lo storico John Tully descrive come i lavoratori locali malesi, cinesi e dayak venissero pagati poco per il pericoloso lavoro di abbattimento degli alberi e la lenta raccolta del lattice. 38 Il lattice veniva lavorato e poi venduto attraverso i mercati commerciali di Singapore al mercato britannico, dove veniva trasformato, tra le altre cose, in lunghe guaine per cavi sottomarini.
Una gutta palaquium matura poteva produrre circa 300 grammi di lattice. Ma nel 1857, il primo cavo transatlantico era lungo circa 3000 km e pesava 2000 tonnellate, il che richiedeva circa 250 tonnellate di guttaperca. Per produrre una sola tonnellata di questo materiale erano necessari circa 900.000 tronchi d’albero. Le giungle della Malesia e di Singapore vennero spogliate e all’inizio degli anni Ottanta del XIX secolo la gutta perca del Palaquium era scomparsa. In un ultimo tentativo di salvare la propria catena di approvvigionamento, nel 1883 gli inglesi promossero un divieto per fermare la raccolta del lattice, ma l’albero era già estinto. 39
Il disastro ambientale vittoriano della guttaperca, dalle prime origini della società dell’informazione globale, mostra come le relazioni tra la tecnologia e la sua materialità, gli ambienti e le diverse forme di sfruttamento siano impregnate. Proprio come i vittoriani hanno provocato un disastro ecologico per i loro primi cavi, così l’estrazione di terre rare e le catene di approvvigionamento globali mettono ulteriormente a rischio il delicato equilibrio ecologico della nostra epoca. Dai materiali utilizzati per costruire la tecnologia che consente la società contemporanea in rete, all’energia necessaria per trasmettere, analizzare e immagazzinare i dati che scorrono attraverso l’enorme infrastruttura, alla materialità dell’infrastruttura: queste connessioni profonde e i costi sono più significativi e hanno una storia molto più lunga di quella solitamente rappresentata nell’immaginario aziendale dell’IA. 40
 Palaquium gutta
Palaquium gutta
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
XVII
I sistemi di intelligenza artificiale su larga scala consumano enormi quantità di energia. Tuttavia, i dettagli materiali di questi costi rimangono vaghi nell’immaginario sociale. Rimane difficile ottenere dettagli precisi sulla quantità di energia consumata dai servizi di cloud computing. Un rapporto di Greenpeace afferma che: “Uno dei maggiori ostacoli alla trasparenza del settore è rappresentato da Amazon Web Services (AWS). La più grande azienda di cloud computing al mondo rimane quasi del tutto non trasparente sull’impronta energetica delle sue enormi operazioni. Tra i fornitori globali di cloud, solo AWS si rifiuta ancora di rendere pubblici i dettagli di base sulle prestazioni energetiche e sull’impatto ambientale associato alle sue operazioni”. 41
Come agenti umani, siamo visibili in quasi tutte le interazioni con le piattaforme tecnologiche. Siamo sempre tracciati, quantificati, analizzati e mercificati. Ma in contrasto con la visibilità degli utenti, i dettagli precisi sulle fasi di nascita, vita e morte dei dispositivi in rete sono oscurati. Con i dispositivi emergenti, come l’Echo, che si affidano a un’infrastruttura IA centralizzata e lontana dalla vista, ancora più dettagli cadono nell’ombra.
Mentre i consumatori si abituano a un piccolo dispositivo hardware nel loro salotto, o a un’applicazione telefonica, o a un’auto semi-autonoma, il vero lavoro viene svolto all’interno di sistemi di apprendimento automatico che sono generalmente lontani dall’utente e totalmente invisibili a quest’ultimo. In molti casi, la trasparenza non servirebbe a molto: senza forme di scelta reale e di responsabilità aziendale, la semplice trasparenza non sposterà il peso delle attuali asimmetrie di potere. 42
I risultati dei sistemi di apprendimento automatico sono prevalentemente non rendicontabili e non governati, mentre gli input sono enigmatici. A un osservatore casuale, sembra che costruire sistemi basati sull’IA o sull’apprendimento automatico non sia mai stato così facile come oggi. La disponibilità di strumenti open-source per farlo, in combinazione con la potenza di calcolo affittabile attraverso superpotenze del cloud come Amazon (AWS), Microsoft (Azure) o Google (Google Cloud), sta facendo nascere la falsa idea della “democratizzazione” dell’IA. Mentre gli strumenti di apprendimento automatico “off the shelf”, come TensorFlow, stanno diventando più accessibili dal punto di vista della creazione del proprio sistema, le logiche sottostanti a tali sistemi e i set di dati per il loro addestramento sono accessibili e controllati da pochissime entità. Nella dinamica di raccolta dei set di dati attraverso piattaforme come Facebook, gli utenti alimentano e addestrano le reti neurali con dati comportamentali, voce, immagini e video taggati o dati medici. In un’epoca di estrattivismo, il valore reale di questi dati è controllato e sfruttato da pochissimi soggetti al vertice della piramide.
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
XVIII
Quando si utilizzano enormi insiemi di dati per addestrare i sistemi di intelligenza artificiale, le singole immagini e i video coinvolti vengono comunemente etichettati e contrassegnati. 43 Ci sarebbe molto da dire sul modo in cui questo processo di etichettatura abroga e cristallizza il significato e, inoltre, sul modo in cui questo processo è guidato dai lavoratori dei click che vengono pagati frazioni di centesimo per questo lavoro digitale a cottimo.
Nel 1770, l’inventore ungherese Wolfgang von Kempelen costruì una macchina per giocare a scacchi nota come Turco meccanico. Il suo obiettivo, in parte, era quello di impressionare l’imperatrice Maria Teresa d’Austria. Questo dispositivo era in grado di giocare a scacchi contro un avversario umano ed ebbe un successo spettacolare vincendo la maggior parte delle partite giocate durante le sue dimostrazioni in Europa e nelle Americhe per quasi nove decenni. Ma il Turco Meccanico era un’illusione che permetteva a un maestro di scacchi umano di nascondersi all’interno della macchina e di farla funzionare. Circa 160 anni più tardi, Amazon.com ha lanciato la sua piattaforma di crowdsourcing basata su micropagamenti con lo stesso nome. Secondo Ayhan Aytes, la motivazione iniziale di Amazon per costruire Mechanical Turk è emersa dopo il fallimento dei suoi programmi di intelligenza artificiale nel compito di trovare pagine di prodotti duplicate sul suo sito web di vendita al dettaglio. 44 Dopo una serie di tentativi inutili e costosi, gli ingegneri del progetto si sono rivolti agli esseri umani per lavorare dietro ai computer all’interno di un sistema razionalizzato basato sul web. 45 L’officina digitale Amazon Mechanical Turk emula i sistemi di intelligenza artificiale controllando, valutando e correggendo i processi di apprendimento automatico con la forza del cervello umano. Con Amazon Mechanical Turk, agli utenti può sembrare che un’applicazione utilizzi un’intelligenza artificiale avanzata per svolgere dei compiti. Ma è più vicina a una forma di “intelligenza artificiale”, guidata da una forza lavoro remota, dispersa e mal pagata che aiuta i clienti a raggiungere i loro obiettivi aziendali. Come osservato da Aytes, “in entrambi i casi [sia il Mechanical Turk del 1770 che la versione contemporanea del servizio di Amazon] le prestazioni dei lavoratori che animano l’artificio sono oscurate dallo spettacolo della macchina”. 46
Questo tipo di lavoro invisibile e nascosto, in outsourcing o in crowdsourcing, celato dietro le interfacce e mimetizzato all’interno dei processi algoritmici, è ormai comune, in particolare nel processo di etichettatura di migliaia di ore di archivi digitali per alimentare le reti neurali. A volte questo lavoro è interamente non retribuito, come nel caso del reCAPTCHA di Google. In un paradosso che molti di noi hanno sperimentato, per dimostrare di non essere un agente artificiale, si è costretti ad addestrare gratuitamente il sistema AI di riconoscimento delle immagini di Google, selezionando più caselle che contengono numeri civici, o automobili, o case.
Come vediamo ripetersi in tutto il sistema, le forme contemporanee di intelligenza artificiale non sono poi così artificiali. Possiamo parlare del duro lavoro fisico dei lavoratori delle miniere e del lavoro ripetitivo delle catene di montaggio, del lavoro cibernetico nei centri di distribuzione e delle officine cognitive piene di programmatori in outsourcing in tutto il mondo, del lavoro in crowdsourcing poco pagato dei lavoratori di Mechanical Turk o del lavoro immateriale non retribuito degli utenti. A ogni livello, la tecnologia contemporanea è profondamente radicata nello sfruttamento dei corpi umani e si regge su di esso.
 Turco Meccanico
Turco Meccanico
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
XIX
Nel suo racconto di un solo paragrafo “Sull’esattezza nella scienza”, Jorge Luis Borges ci presenta un impero immaginario in cui la scienza cartografica è diventata così sviluppata e precisa da aver bisogno di una mappa della stessa scala dell’impero stesso. 47
“In quell’impero, l’arte della cartografia raggiunse una tale perfezione che la mappa di una singola provincia occupava la totalità di una città, e la mappa dell’impero la totalità di una provincia. Col tempo, quelle mappe inconcepibili non soddisfacevano più, e le Gilde dei Cartografi realizzarono una mappa dell’Impero le cui dimensioni erano quelle dell’Impero e che coincidevano punto per punto con esso. Le generazioni successive, che non amavano lo studio della cartografia come i loro antenati, videro che quella vasta mappa era inutile, e non senza una certa spietatezza la consegnarono alle inclemenze del sole e degli inverni. Nei deserti dell’Occidente, ancora oggi, ci sono brandelli di quella mappa, abitati da animali e mendicanti; in tutta la terra non c’è nessun’altra reliquia delle discipline della geografia”.
Gli attuali approcci all’apprendimento automatico sono caratterizzati dall’aspirazione a mappare il mondo, una quantificazione completa dei regimi visivi, uditivi e di riconoscimento della realtà. Dal modello cosmologico dell’universo al mondo delle emozioni umane interpretate attraverso i più piccoli movimenti muscolari del volto umano, tutto diventa oggetto di quantificazione. Jean-François Lyotard ha introdotto l’espressione “affinità con l’infinito” per descrivere come l’arte contemporanea, la tecno-scienza e il capitalismo condividano la stessa aspirazione a spingere i confini verso un orizzonte potenzialmente infinito. 48 La seconda metà del XIX secolo, con la sua attenzione alla costruzione di infrastrutture e alla transizione disomogenea verso la società industrializzata, ha generato enormi ricchezze per un ristretto numero di magnati industriali che hanno monopolizzato lo sfruttamento delle risorse naturali e i processi produttivi.
Il nuovo orizzonte infinito è l’estrazione dei dati, l’apprendimento automatico e la riorganizzazione delle informazioni attraverso sistemi di intelligenza artificiale che combinano l’elaborazione umana e quella meccanica. I territori sono dominati da poche mega-aziende globali, che stanno creando nuove infrastrutture e meccanismi per l’accumulo di capitale e lo sfruttamento delle risorse umane e planetarie.
Questa sete sfrenata di nuove risorse e campi di sfruttamento cognitivo ha spinto la ricerca di strati sempre più profondi di dati che possono essere utilizzati per quantificare la psiche umana, conscia e inconscia, privata e pubblica, idiosincratica e generale. In questo modo, abbiamo assistito all’emergere di molteplici economie cognitive: l’economia dell’attenzione, 49 l’economia della sorveglianza, l’economia della reputazione 50 e l’economia delle emozioni, nonché la quantificazione e la mercificazione della fiducia e delle prove attraverso le criptovalute.
Il processo di quantificazione si estende sempre più al mondo affettivo, cognitivo e fisico dell’uomo. Esistono set di addestramento per il rilevamento delle emozioni, per la somiglianza familiare, per seguire l’invecchiamento di un individuo e per le azioni umane come sedersi, salutare, alzare un bicchiere o piangere. Ogni forma di dati anagrafici – compresi quelli forensi, biometrici, sociometrici e psicometrici – viene acquisita e registrata in database per l’addestramento delle IA. Questa quantificazione spesso si basa su basi molto limitate: insiemi di dati come AVA che mostrano principalmente le donne nella categoria di azioni “giocare con i bambini” e gli uomini nella categoria “prendere a calci una persona”. Gli insiemi di addestramento per i sistemi di IA pretendono di raggiungere la natura a grana fine della vita quotidiana, ma ripetono i modelli sociali più stereotipati e limitati, reinscrivendo una visione normativa del passato umano e proiettandola nel futuro umano.
 Quantificazione della natura
Quantificazione della natura
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
XX
La “recinzione” della biodiversità e della conoscenza è il passo finale di una serie di recinzioni iniziate con l’avvento del colonialismo. La terra e le foreste sono state le prime risorse a essere ‘racchiuse’ e convertite da beni comuni a merci. In seguito, le risorse idriche sono state “racchiuse” attraverso dighe, estrazione di acque sotterranee e schemi di privatizzazione. Ora è il turno della biodiversità e della conoscenza di essere ‘racchiuse’ attraverso i diritti di proprietà intellettuale (DPI)”, spiega Vandana Shiva. 51 Secondo le parole di Shiva, “la distruzione dei beni comuni è stata essenziale per la rivoluzione industriale, per fornire un approvvigionamento di risorse naturali come materia prima all’industria. Un sistema di supporto alla vita può essere condiviso, non può essere posseduto come proprietà privata o sfruttato per profitto privato. I beni comuni, quindi, dovevano essere privatizzati e la base di sostentamento delle persone in questi beni comuni doveva essere appropriata, per alimentare il motore del progresso industriale e dell’accumulazione di capitale”. 52
Mentre Shiva si riferisce alla chiusura della natura da parte dei diritti di proprietà intellettuale, lo stesso processo si sta verificando con l’apprendimento automatico – un’intensificazione della natura quantificata. La nuova corsa all’oro nel contesto dell’intelligenza artificiale consiste nel racchiudere diversi campi del sapere, del sentire e dell’agire umano, al fine di catturare e privatizzare tali campi. Quando nel novembre 2015 DeepMind Technologies Ltd. ha avuto accesso alle cartelle cliniche di 1,6 milioni di pazienti identificabili dell’ospedale Royal Free, abbiamo assistito a una particolare forma di privatizzazione: l’estrazione del valore della conoscenza.53 Un set di dati può ancora essere di proprietà pubblica, ma il meta-valore dei dati – il modello creato da essi – è di proprietà privata. Sebbene ci siano molte buone ragioni per cercare di migliorare la salute pubblica, c’è un rischio reale se ciò avviene a costo di una privatizzazione furtiva dei servizi medici pubblici. Si tratta di un futuro in cui il lavoro umano esperto a livello locale nel sistema pubblico viene aumentato e talvolta sostituito da sistemi di intelligenza artificiale aziendali centralizzati e di proprietà privata, che utilizzano i dati pubblici per generare enormi ricchezze per pochi.
 Corporate border
Corporate border
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
XXI
In questo momento del XXI secolo, assistiamo a una nuova forma di estrattivismo che è ben avviata: una forma di estrattivismo che raggiunge gli angoli più remoti della biosfera e gli strati più profondi dell’essere cognitivo e affettivo umano. Molte delle ipotesi sulla vita umana formulate dai sistemi di apprendimento automatico sono ristrette, normative e cariche di errori. Tuttavia, essi stanno iscrivendo e costruendo tali presupposti in un nuovo mondo e svolgeranno sempre più un ruolo nel modo in cui vengono distribuite le opportunità, la ricchezza e la conoscenza.
Lo stack necessario per interagire con un Amazon Echo va ben oltre lo “stack tecnico” a più livelli di modellazione dei dati, hardware, server e reti. Lo stack completo si estende molto di più al capitale, al lavoro e alla natura, e richiede un’enorme quantità di ciascuno di essi. I veri costi di questi sistemi – sociali, ambientali, economici e politici – rimangono nascosti e potrebbero rimanere tali per qualche tempo.
Offriamo questa mappa e questo saggio come un modo per iniziare a vedere attraverso una gamma più ampia di estrazioni del sistema. La scala richiesta per costruire sistemi di intelligenza artificiale è troppo complessa, troppo oscurata dalle leggi sulla proprietà intellettuale e troppo impantanata nella complessità logistica per essere compresa appieno in questo momento. Eppure vi attingete ogni volta che impartite un semplice comando vocale a un piccolo cilindro nel vostro salotto: “Alexa, che ore sono?”.
E così il ciclo continua.
https://anatomyof.ai/
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
Note
- 1 Kate Crawford is a Distinguished Research Professor at New York University, a Principal Researcher at Microsoft Research New York, and the co-founder and co-director of the AI Now Institute at NYU.
- 2 Vladan Joler is a professor at the Academy of Arts at the University of Novi Sad and founder of SHARE Foundation. He is leading SHARE Lab, a research and data investigation lab for exploring different technical and social aspects of algorithmic transparency, digital labor exploitation, invisible infrastructures, and technological black boxes.
- 3 Amazon advertising campaign, “All-New Amazon Echo”, September 27, 2017, https://www.youtube.com/watch?v=IyvZ41XjUjY.
- 4 Emily Achtenberg, “Bolivia Bets on State-Run Lithium Industry,” NACLA, November 15, 2010, https://nacla.org/news/bolivia-bets-state-run-lithium-industry.
- 5 Christine Negroni, “How to Determine the Power Rating of Your Gadget’s Batteries,” The New York Times, December 22, 2017, https://www.nytimes.com/2016/12/26/business/lithium-ion-battery-airline-safety.html.
- 6 Jessica Shankleman et al., “We’re Going to Need More Lithium,” Bloomberg, September 7, 2017, https://www.bloomberg.com/graphics/2017-lithium-battery-future/.
- 7 Nicola Clark and Simon Wallis, “Flamingos, Salt Lakes and Volcanoes: Hunting for Evidence of Past Climate Change on the High Altiplano of Bolivia,” Geology Today 33, no. 3 (May 1, 2017): 104, https://doi.org/10.1111/gto.12186.
- 8 Kate Davies and Liam Young, Tales from the Dark Side of the City: The Breastmilk of the Volcano Bolivia and the Atacama Desert Expedition (London: Unknown Fields, 2016).
- 9 Vincent Mosco, To the Cloud: Big Data in a Turbulent World (Boulder: Paradigm, 2014).
- 10 Sandro Mezzadra and Brett Neilson, “On the Multiple Frontiers of Extraction: Excavating Contemporary Capitalism,” Cultural Studies 31, no. 2–3 (May 4, 2017): 185, https://doi.org/10.1080/09502386.2017.1303425.
- 11 Lamberto Tronchin, “The ‘Phonurgia Nova’ of Athanasius Kircher: The Marvellous Sound World of 17th Century,” Proceedings of Meetings on Acoustics 4, no. 1 (June 29, 2008), 4: 015002, https://doi.org/10.1121/1.2992053.
- 12 Marshall McLuhan, Understanding Media: The Extensions of Man (New York: Signet Books, 1964).
- 13 Jussi Parikka, A Geology of Media (Minneapolis: University Of Minnesota Press, 2015), vii-viii.
- 14 Chris Ely, “The Life Expectancy of Electronics,” Consumer Technology Association, September 16, 2014, https://www.cta.tech/News/Blog/Articles/2014/September/The-Life-Expectancy-of-Electronics.aspx.
- 15 Christian Fuchs, Digital Labor and Karl Marx (London: Routledge, 2014).
- 16 “This Is What We Die For: Human Rights Abuses in the Democratic Republic of the Congo Power the Global Trade in Cobalt” (London: Amnesty International, 2016), https://www.amnesty.org/download/Documents/AFR6231832016ENGLISH.PDF. For an anthropological description of these mining processes, see: Jeffrey W. Mantz, “Improvisational Economies: Coltan Production in the Eastern Congo,” Social Anthropology 16, no. 1 (February 1, 2008): 34–50, https://doi.org/10.1111/j.1469-8676.2008.00035.x.
- 17 Julia Glum, “The Median Amazon Employee’s Salary Is $28,000. Jeff Bezos Makes More Than That in 10 Seconds,” Time, May 2, 2018, http://time.com/money/5262923/amazon-employee-median-salary-jeff-bezos/.
- 18F rank Pasquale, The Black Box Society: The Secret Algorithms That Control Money and Information (Cambridge, MA: Harvard University Press, 2016).
- 19 Mark Graham and Håvard Haarstad, “Transparency and Development: Ethical Consumption through Web 2.0 and the Internet of Things,” Information Technologies & International Development 7, no. 1 (March 10, 2011): 1.
- 20 “Intel’s Efforts to Achieve a ‘Conflict Free’ Supply Chain” (Santa Clara, CA: Intel Corporation, May 2018), https://www.intel.com/content/www/us/en/corporate-responsibility/conflict-minerals-white-paper.html.
- 21 “We Are Working to Make Our Supply Chain ‘Conflict-Free,’” Philips, 2018, https://www.philips.com/a-w/about/company/suppliers/supplier-sustainability/our-programs/conflict-minerals.html.
- 22 David S. Abraham, The Elements of Power: Gadgets, Guns, and the Struggle for a Sustainable Future in the Rare Metal Age, Reprint edition (Yale University Press, 2017), 89.
- 23 “Responsible Minerals Sourcing,” Dell, 2018, http://www.dell.com/learn/us/en/uscorp1/conflict-minerals?s=corp.
- 24 “Apple Supplier Responsibility 2018 Progress Report” (Cupertino CA: Apple, 2018), https://www.apple.com/supplier-responsibility/pdf/Apple_SR_2018_Progress_Report.pdf.
- 25 Alexander Klose, The Container Principle: How a Box Changes the Way We Think, trans. Charles Marcum II (Cambridge, MA: The MIT Press, 2015).
- 26 “Review of Maritime Transport 2017” (New York and Geneva: United Nations, 2017), http://unctad.org/en/PublicationsLibrary/rmt2017_en.pdf.
- 27Z oë Schlanger, “If Shipping Were a Country, It Would Be the Sixth-Biggest Greenhouse Gas Emitter,” Quartz, April 17, 2018.
- 28 John Vidal, “Health Risks of Shipping Pollution Have Been ‘Underestimated,’” The Guardian, April 9, 2009, sec. Environment, http://www.theguardian.com/environment/2009/apr/09/shipping-pollution.
- 29 “Containers Lost At Sea – 2017 Update” (World Shipping Council, July 10, 2017), http://www.worldshipping.org/industry-issues/safety/Containers_Lost_at_Sea_-_2017_Update_FINAL_July_10.pdf.
- 30 Rose George, Ninety Percent of Everything: Inside Shipping, the Invisible Industry That Puts Clothes on Your Back, Gas in Your Car, and Food on Your Plate (New York: Metropolitan Books, 2013), 22. Similar to our habit to neglect materiality of internet infrastructure and information technology, shipping industry is rarely represented in popular culture. Rose George calls this condition, “sea blindness” (2013, 4).
- 31 id., 175.
- 32 Ibid., Ib 176.
- 33 Chris Lo, “The False Monopoly: China and the Rare Earths Trade,” Mining Technology, August 19, 2015, https://www.mining-technology.com/features/featurethe-false-monopoly-china-and-the-rare-earths-trade-4646712/.
- 34 Kate Hodal, “Death Metal: Tin Mining in Indonesia,” The Guardian, November 23, 2012, http://www.theguardian.com/environment/2012/nov/23/tin-mining-indonesia-bangka.
- 35 Cam Simpson, “The Deadly Tin Inside Your Smartphone,” Bloomberg, August 24, 2012, https://www.bloomberg.com/news/articles/2012-08-23/the-deadly-tin-inside-your-smartphone.
- 36 Marcus Wohlsen, “A Rare Peek Inside Amazon’s Massive Wish-Fulfilling Machine,” Wired, June 16, 2014, https://www.wired.com/2014/06/inside-amazon-warehouse/.
- 37 Wurman, Peter R. et al., System and Method for Transporting Personnel Within an Active Workspace, US 9,280,157 B2 (Reno, NV, filed September 4, 2013, and issued March 8, 2016), http://pdfpiw.uspto.gov/.piw?Docid=09280157.
- 38 John Tully, “A Victorian Ecological Disaster: Imperialism, the Telegraph, and Gutta-Percha,” Journal of World History 20, no. 4 (December 23, 2009): 559–79, https://doi.org/10.1353/jwh.0.0088.
- 39 Ibid., 574.
- 40 See Nicole Starosielski, The Undersea Network (Durham: Duke University Press Books, 2015).
- 41 Gary Cook, “Clicking Clean: Who Is Winning the Race to Build a Green Internet?” (Washington, DC: Greenpeace, January 2017), 30, https://storage.googleapis.com/p4-production-content/international/wp-content/uploads/2017/01/35f0ac1a-clickclean2016-hires.pdf.
- 42 Mike Ananny and Kate Crawford, “Seeing without knowing: Limitations of the transparency ideal and its application to algorithmic accountability,” New Media & Society 20.3 (2018): 973-989.
- 43 Olga Russakovsky et al., “ImageNet Large Scale Visual Recognition Challenge,” International Journal of Computer Vision 115, no. 3 (December 1, 2015): 216, https://doi.org/10.1007/s11263-015-0816-y.
- 44 Ayhan Aytes, “Return of the Crowds: Mechanical Turk and Neoliberal States of Exception,” in Digital Labor: The Internet as Playground and Factory, ed. Trebor Scholz (London: Routledge, 2012), 80.
- 45 Jason Pontin, “Artificial Intelligence, With Help From the Humans,” The New York Times, March 25, 2007, sec. Business Day, https://www.nytimes.com/2007/03/25/business/yourmoney/25Stream.html.
- 46 Aytes, “Return of the Crowds,” 81.
- 47 Jorge Luis Borges, “On Exactitude in Science,” in Collected Fictions, trans. Andrew Hurley (New York: Penguin, 1999), 325.
- 48 Jean Francois Lyotard, “Presenting the Unpresentable: The Sublime,” Artforum, April 1982.
- 49 Yves Citton, The Ecology of Attention (Cambridge, UK: Polity, 2017).
- 50 Shoshana Zuboff, “Big Other: Surveillance Capitalism and the Prospects of an Information Civilization,” Journal of Information Technology 30, no. 1 (March 1, 2015): 75–89, https://doi.org/10.1057/jit.2015.5.
- 51 Vandana Shiva, The Enclosure and Recovery of The Commons: Biodiversity, Indigenous Knowledge, and Intellectual Property Rights (Research Foundation for Science, Technology, and Ecology, 1997).
- 52 Vandana Shiva, Protect or Plunder: Understanding Intellectual Property Rights (New York: Zed Books, 2001).
- 53 Alex Hern, “Royal Free Breached UK Data Law in 1.6m Patient Deal with Google’s DeepMind,” The Guardian, July 3, 2017, sec. Technology, http://www.theguardian.com/technology/2017/jul/03/google-deepmind-16m-patient-royal-free-deal-data-protection-act.
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
Download
Versione PDF della mappa
https://anatomyof.ai/img/ai-anatomy-map.pdf
__________________________________________________________________________
https://anatomyof.ai/img/ai-anatomy-publication.pdf
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
Riconoscimenti e ringraziamenti
__________________________________________________________________________
Authors: Kate Crawford and Vladan Joler
Maps and design: Vladan Joler and Kate Crawford
Published by: SHARE Lab, SHARE Foundation (https://labs.rs) and The AI Now Institute, NYU (https://ainowinstitute.org/)
Full citation: Kate Crawford and Vladan Joler, “Anatomy of an AI System: The Amazon Echo As An Anatomical Map of Human Labor, Data and Planetary Resources,” AI Now Institute and Share Lab, (September 7, 2018) https://anatomyof.ai
Ringraziamenti: I nostri profondi ringraziamenti vanno a Michelle Thorne e Jon Rogers della Mozilla Foundation, che ci hanno invitato a un ritiro nell’estate 2017 dove abbiamo concettualizzato per la prima volta questo progetto. Grazie a Joana Moll e Meredith Whittaker per i loro input e le loro ispirazioni sulle prime bozze di questo testo. Grazie anche a tutti coloro che da allora ci hanno fornito feedback, supporto e spunti, tra cui Alex Campolo, Casey Gollan, Gretchen Krueger, Trevor Paglen e Sarah Myers West dell’AI Now Institute e Olivia Solis, Andrej Petrovski e Milica Jovanovic dello SHARE Lab e tutti i meravigliosi collaboratori della SHARE Foundation.
Infine, grazie a Irini Papadimitriou e a tutto lo staff curatoriale del V&A Museum. La mappa e il saggio saranno esposti nell’ambito della mostra “Artificially Intelligent” dal 6 settembre al 31 dicembre 2018.
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
Anatomia di un sistema di intelligenza artificiale
Threat Modeling workshop
Cos’è il threat modeling
È un processo con cui identificare potenziali minacce e vulnerabilità, valutare quanto sono serie/probabili nel caso specifico, metterle in una scala di priorità, e ridurre il rischio che si avverino prendendo delle contromisure. In genere lo si fa per sistemi/software/prodotti, e al riguardo c’è una discreta letteratura in materia (ad esempio, Threat Modeling: Designing for Security di Adam Shostack, un manuale fondamentale, e piuttosto tecnico, rivolto soprattutto a sviluppatori ecc).
Ma lo si può applicare anche a organizzazioni e persone, sebbene qui la disciplina sia meno sistematizzata e nel caso delle persone tenda a sovrapporsi alle misure per mettere in sicurezza le proprie attività online (denominate operation security o opsec).
Qui in particolare ci interessa l’applicazione alle persone. In questa accezione, tutti noi già facciamo threat modeling (le donne poi lo fanno tantissimo). Quando valutiamo che via prendere per tornare la sera, quanto è sicura, quanto ci espone tornare a piedi da soli, che mezzi abbiamo eventualmente per evitare (o difenderci da) una aggressione. Questo è threat modeling di strada.
Siamo invece meno abituati ad applicarlo nella nostra vita digitale. Eppure imparare a farlo aiuta molto di più della solita lista di consigli, che finiscono con l’essere indicazioni generiche e inascoltate. Il threat modeling invece è alla base di una cultura della sicurezza, anche individuale.
Dunque proviamo a fare un esercizio assieme. Partiamo dal grafico sottostante.
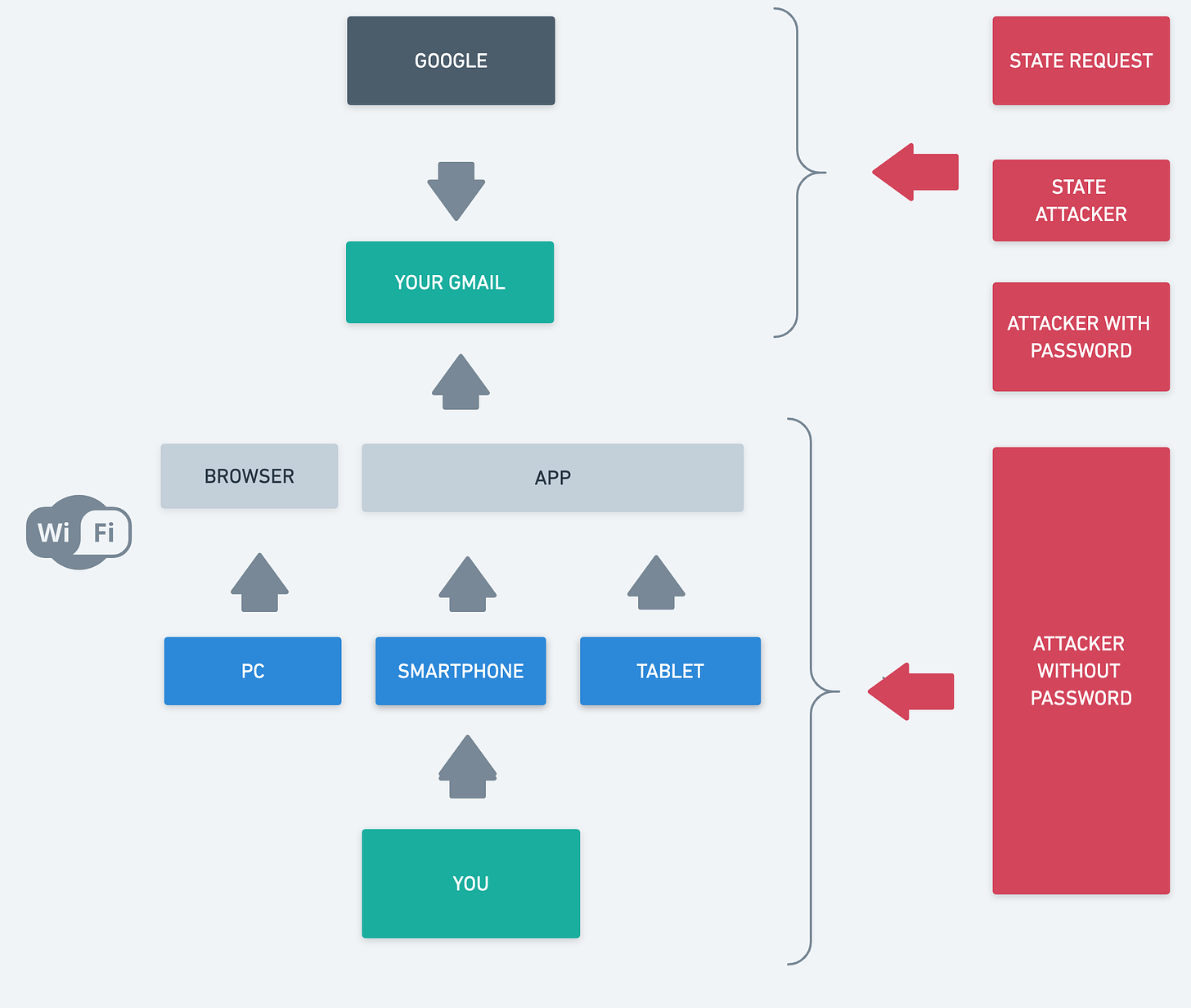
Potremmo considerarlo un frammento di una attività di threat modeling per una persona. Un frammento (semplificato qua al massimo) che parte da uno dei suoi asset più importanti, la mail (ho preso per comodità Gmail, vista la sua diffusione).
Nel grafico troverete che ogni freccia indica un percorso (o un pezzetto di percorso) per accedere alla vostra casella Gmail. Ovvero YOU (TU) detentore dell’account ci accedi di solito usando un pc, uno smartphone e un tablet (almeno nella nostra simulazione). Ognuno di questi usa a sua volta una app o un browser (e una connessione, ad esempio un punto d’accesso Wi-Fi). Che si connette a Gmail.
Ma anche Google può accedere a Gmail (che lo faccia o meno non importa, interessa la possibilità per ora).
E anche un attaccante che abbia le credenziali (semplificate qui con password).
E anche un attaccante che non abbia le nostre credenziali ma riesca a infilarsi nel nostro percorso per accedere a Gmail (ad esempio, usando uno dei nostri apparecchi o software. Anche qua il termine usare è volutamente vago: si va dall’infezione con un trojan veicolata navigando col browser su un sito malevolo a qualcuno che acceda fisicamente al nostro tablet incustodito). Ma l’attacco potrebbe anche essere direttamente contro di noi: qualcuno che ci prenda il telefono di mano fisicamente; o ci inganni con una operazione di social engineering per farsi consegnare la password; o ci minacci fisicamente per avere la password.
Ora il threat modeling sarà:
– fare una lista delle possibilità di attacco/vulnerabilità dato questo schema che contempla i modi in cui noi o altri accediamo al nostro Gmail;
– valutare quelli che per noi sono gli attacchi/vulnerabilità più probabili, scartare quelli improbabili o comunque quasi impossibili da rimediare, e su tutti gli altri applicare dei rimedi – in gergo si dice che applichiamo dei controlli, ovvero delle contromisure contro questi attacchi, e le contromisure possono essere tecniche (ad esempio, cifratura) o procedurali (non rivelo la password a uno al telefono che si finge MrBigGoogle, ogni riferimento a Carrie è puramente casuale).
Detto altrimenti (usando l’aiuto da casa di Andrew Lee-Thorp in questa presentazione video sul threat modeling):
- costruisci il modello, una rappresentazione del sistema
- poniti delle domande sul sistema (essenzialmente: cosa potrebbe andare storto?)
- identifica come mettere a posto i difetti trovati
Tutto chiaro? Iniziamo.
Ripartiamo dall’elenco di ciò che dobbiamo analizzare perché può portare, direttamente o indirettamente, al nostro Gmail. Agevolo grafico. Ognuna di queste caselle/riquadri colorati richiederebbe una analisi a se stante probabilmente. Inoltre ce ne potrebbero essere molte altre a seconda delle preferenze d’uso dell’utente (esempio: usa un servizio cloud per il backup delle mail? Usa un password manager? ecc ecc)
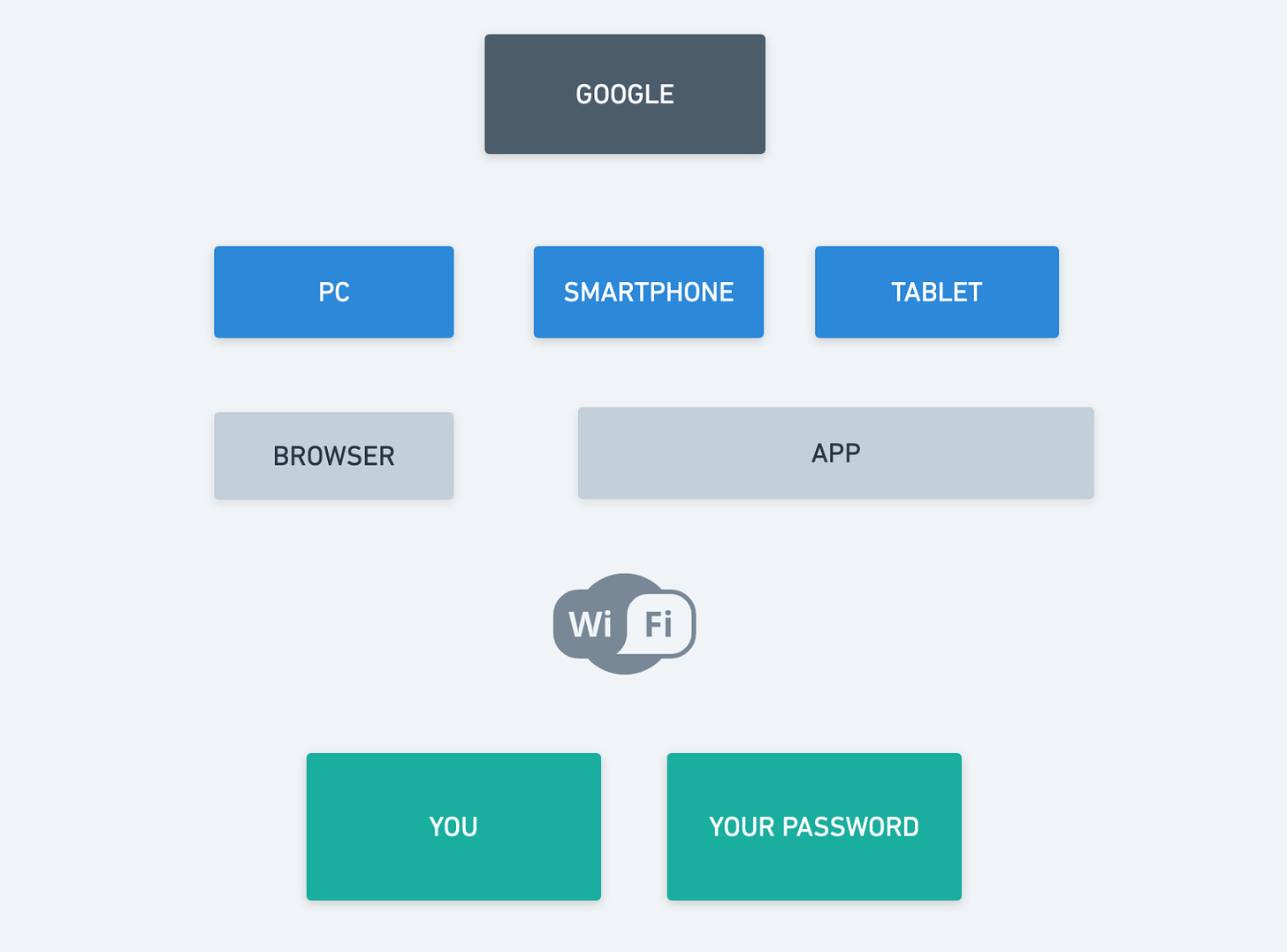
Ora immaginiamo solo alcune situazioni (non tutte ok?).
ATTACCANTE CON LA PASSWORD
Per la maggior parte di voi (di noi) l’attacco più probabile sarà quello dell’attaccante con password, cioè che è già in possesso della nostra password (vedi riquadro YOUR PASSWORD nel grafico). Quindi dovremo lavorare per evitare che questo accada. Normalmente un attaccante ha la nostra password perché:
1) gliela abbiamo detta noi (rivelandola a ex convivente, collega ecc, scrivendola su un post-it ecc)
2) è una password che può essere indovinata da un umano (è il nome del nostro gatto molto amato e instagrammato seguito dal nostro anno di nascita, appena celebrato con compleanno e torta su Facebook) o da un programma (che prova tutte le parole esistenti ecc)
3) è una password difficile da indovinare ma non è unica, la usiamo anche sul forum di vattelapesca, sul sito degli scacchi cui ci siamo appena iscritti trascinati dall’entusiasmo per una serie Netflix, sul sito di dating per cuori spezzati dal Covid. Se uno di questi viene “bucato” da qualcuno e non protegge adeguatamente la password, l’attaccante potrà provare a usarla sul nostro Gmail (la pratica esecrabile di usare la stessa password su più account si chiama password reuse, e vi assicuro che ci sono ancora più leak in circolo figli del password reuse che virologi in tv).
4) password unica e difficile ma poi nelle opzioni recupero password ho risposto alle domande di sicurezza che mi chiedono il nome dell’asilo che frequentavo mettendo davvero quello (ma come fate a ricordarvelo poi?), e un attaccante motivato ha scoperto la risposta giusta da inserire.
5) gli esempi possono essere sempre più complessi: se usiamo un password manager (uno strumento che ti fa salvare tutte le password in un posto solo) e sopra ci salviamo anche la nostra password di Gmail dobbiamo sapere che la sicurezza di Gmail dipenderà dalla sicurezza della password con cui entriamo nel password manager (che probabilmente dovremmo aggiungere da qualche parte nel grafico sopra, essendo un’ulteriore via di accesso al nostro Gmail).
(PS: il password manager, se usato bene, è uno dei principali strumenti per alzare le vostre difese (insieme all’autenticazione a due fattori). Ce ne sono di vari tipi (qua una lista con pro e contro – PC Mag). Inoltre una volta che si inizia a usarlo scoprirete che è estremamente comodo.)
Ok, ora che abbiamo visto sopra alcuni casi (i vari 1,2, 3, 4, 5) applichiamo subito per ognuno delle contromisure che potranno essere tecniche o procedurali (mentre in contemporanea valutiamo la priorità da dare alla varie minacce in base al nostro profilo):
1) decidiamo che non dobbiamo rivelare la password a nessuno, se lo abbiamo fatto la cambiamo (procedurale)
2) cambiamo la password facile mettendone una lunga e difficile, con mix di lettere, numeri e caratteri speciali (tecnico). PS: la password P@ssw0rd! non vale eh
3) facciamo in modo che la nostra password Gmail sia unica (procedurale)
4) non rispondiamo in modo veritiero a domande di sicurezza che possono essere indovinate/ricostruite da altri (procedurale)
5) sulla 5, ma in generale a rinforzo anche delle altre, aggiungiamo l’autenticazione a due fattori. Così anche se qualcuno avrà la nostra password dovrà avere anche un codice generato dal nostro telefono per accedere. Scegliamo dunque di usare una app per generare i codici del nostro secondo fattore. Riduciamo il rischio che qualcuno possa usare il nostro telefono con la app bloccandolo con un pin (con la cifratura).
Se invece immaginiamo per qualche motivo di dover usare solo l’autenticazione a due fattori via sms (e non tramite app), alla nostra analisi dovremo aggiungere una serie di rischi/attacchi connessi al ricevimento dell’sms: l’operatore telefonico (o un suo dipendente) potrebbe essere compromesso/ingannato e permettere un cambio di SIM – SIM swap – richiesto dagli attaccanti che così a quel punto riceverebbero loro l’sms; o l’sms potrebbe essere “intercettato” con attacchi SS7 che sfruttano una nota vulnerabilità del protocollo usato nelle reti telefoniche. (Sul rischio SIM swap, prevalente negli Stati Uniti e in altri Stati, e alcune possibilità per mitigarlo vedi questo articolo di Cybersecurity360).
ATTACCANTE SENZA PASSWORD
SCENARIO A
Lo scenario A è il più diffuso e probabile. È quello in cui l’attaccante cercherà di farsi dare la password da voi senza che ve ne accorgiate. Quindi sarete attaccati direttamente voi (vedi riquadro YOU nel grafico).
Il metodo più diffuso e probabile sarà social engineering, ovvero l’inganno:
1) mail di phishing (finta notifica sicurezza di Gmail che dice che dovete cambiare subito la password perdiana!)
2) sms/messaggio o telefonata di phishing (in gergo, smishing o vishing)
3) altri metodi creativi
La contromisura sarà procedurale:
– non clicco su link sospetti, non inserisco le mie credenziali se non sono sicura che sia Gmail, non vado a cambiare la password da un link nella mail, non mi fido di sconosciuti al telefono anche se assicurano di essere un helpdesk, non accetto caramelle ecc
E tecnica:
– uso autenticazione a due fattori (è vero che il social engineering può riuscire ad aggirarla, ma se ad esempio adotto una chiavetta hardware tipo Yubikey come metodo di autenticazione diventa molto più dura se non impossibile).
SCENARIO B
L’attaccante cercherà di farsi dare la password minacciandovi fisicamente o legalmente (vedi riquadro YOU).
Contromisura procedurale per la minaccia legale:
– un buon avvocato se siete in uno Stato di diritto
Se non siete in uno Stato di diritto, dovete accettare il rischio di dover consegnare la password. Potete minimizzarlo riducendo i dati sensibili presenti sulla vostra mail. O viaggiare (se lo Stato è estero) senza i vostri usuali dispositivi e/o metterci sopra un Gmail secondario. O altro ancora. Ma questa è una soluzione estrema, e se il vostro threat model è quello di comuni mortali probabilmente lo scarterete o comunque sarà in fondo alle vostre priorità.
SCENARIO C
L’attaccante cercherà di accedere direttamente al vostro Gmail passando fisicamente dai vostri apparecchi, ergo tenterà di mettere le mani sui vostri telefoni, tablet, computer (vedi riquadro PC, SMARTPHONE, TABLET).
Contromisura tecnica:
– cifratura disco su tutto
Contromisura procedurale:
– non lascio i miei apparecchi incustoditi, specie se accesi; faccio in modo di inserire il blocco se mi allontano per poco, spengo (per attivare cifratura) se mi allontano di più o se lo trasporto.
(Questo scenario sarà ovviamente in cima alla vostra lista se lavorate in aree condivise, e dovete spesso allontanarvi dal pc per vari motivi; se non vi fidate di chi ha accesso ai vostri spazi; se viaggiate per lavoro, ecc)
SCENARIO D
L’attaccante prova a ottenere le vostre credenziali o comunque a leggervi la posta entrando da remoto nei vostri dispositivi. Può farlo in vari modi:
1) con un link in una mail/messaggio che vi farà installare un trojan
2) con una finta app da scaricare che invece è malevola
3) con una vulnerabilità del vostro software
4) con un aggiornamento malevolo di un software autentico
5) dirottando la vostra navigazione su un sito malevolo senza che ve ne accorgiate
….e in altri modi che non sto ad elencare…
(vedi riquadro SMARTPHONE, TABLET, PC intesi come sistema operativo ma anche BROWSER, APP ecc)
Contromisure tecniche e procedurali:
1) installate un antivirus, non cliccate su link di cui non siete sicuri, aprite allegati all’interno di applicazioni/ambienti sicure
2) non scaricate app e software a caso
3) aggiornate sempre i software, non visitate siti sconosciuti, non col computer su cui volete proteggere dati sensibili
4) in questo caso l’attaccante ha compromesso la supply chain, è di alto livello, sperate di non rientrare in questo threat model e comunque di essere solo un target casuale
4) tendenzialmente, idem come sopra
(Tenete però presente che se il vostro threat model include qualcuno che voglia entrare con un malware nel vostro pc quasi SOLO per leggervi la posta – invece che per cifrare tutto con un ransomware e chiedervi un riscatto, o per entrare nell’internet banking, siete in una alarm zone, in cui dovrete prendere molte altre contromisure… Una parte di giornalisti può essere inclusa in questa categoria, così come alcuni avvocati, legali, consulenti, politici ecc ).
Prendiamo ora ad esempio solo il riquadro TABLET e invertiamo l’ordine del ragionamento.
Avete adottato tutte le contromisure di cui sopra, password forte, autenticazione a due fattori, sul telefono avete una passphrase, il computer è cifrato… ma cosa altro potrebbe andare storto considerato che volete difendere la casella mail? Magari dal tablet vi eravate loggati su Gmail per controllare un giorno la posta mentre eravate chissà dove e di fretta, poi ve ne eravate quasi dimenticati, e il vostro tablet (che usate solo per la didattica a distanza dei figli) non ha PIN di sorta. Un giorno vostro figlio se lo porta a scuola e poi lo dimentica su un muretto. Oppure lo lasciate voi per errore in un bar o su un treno. Se aveste fatto threat modeling, avreste invece considerato che il tablet era uno dei modi per accedere al vostro Gmail e avreste potuto decidere di blindarlo con un PIN o passphrase, o meglio ancora, visto che andava in giro in mano ad altri, di togliere del tutto Gmail dallo stesso.
Ancora, vediamo la casella GOOGLE, ovvero la possibilità di una RICHIESTA STATALE E/O di un ATTACCANTE STATALE.
La maggior parte delle persone probabilmente non avrà questa preoccupazione in cima alla sua lista (specifico che per richiesta e/o attacco statale intendo qualsiasi Stato, non solo il vostro; e che la prima può essere una ingiunzione o altra richiesta legale nell’ambito di una giurisdizione, mentre con attacco intendo un accesso illegale fatto a insaputa della stessa azienda, in genere da parte di una intelligence). Tuttavia se invece vi considerate a rischio dovrete trovare il modo di cifrare le vostre mail sensibili (ce ne sono diversi, qua un elenco di opzioni; e qua un altro). Vale anche per lo scenario in cui non vi fidiate di Google (ma allora fate prima a non usare proprio i suoi servizi).
Bene, abbiamo finito questa prima analisi. Ora andate avanti voi: elencate la vostra lista di asset (di beni per voi preziosi in quanto contenenti vostre info o accessi alle stesse), e provate a esaminare per ognuno chi e come può accedere. E dove potete applicare contromisure. Se alla fine di questo esercizio non vi è salita almeno un po’ di paranoia, allora l’esperimento non è andato a buon fine.
In generale, ricordo ancora che ci si può concentrare: 1) sugli asset (i vostri beni digitali/tecnologici); 2) sugli entry point; 3) sugli attaccanti, e che comunque è qualcosa che in realtà sapete già fare, sempre per citare Shostack. E che la domanda principale da porsi resta: cosa può andare storto?
Ecco qualche risorsa da consultare:
- Threat Modeling: Lessons from Star Wars – Adam Shostack – VIDEO (sempre per un approccio più tecnico, ma comunque una buona introduzione al tema)
- Threat Modeling Cheat Sheet (tecnico, ma con una intro su terminologia e metodologie)
- How I learned to stop worrying (mostly) and love my threat model (per utenti comuni, il threat modeling secondo un approccio usato anche qua)
- Surveillance Self Defense: Threat Modeling – EFF (per attivisti, giornalisti, utenti vari)
- Security for Journalists, Part Two: Threat Modeling (ottimo per giornalisti, anche se i riferimenti ai tool possono essere un po’ datati).
Carola Frediani
FLoC di Google è un’idea terribile EFF
FLoC di Google è un’idea terribile Di Bennett Cyphers – 3 marzo 2021

Google’s FLoC Is a Terrible Idea
Il cookie di terze parti sta morendo e Google sta cercando di crearne un sostituto.
Nessuno dovrebbe piangere la morte del cookie come lo conosciamo. Per più di due decenni, il cookie di terze parti è stato il fulcro di un sistema oscuro, squallido e multimiliardario di sorveglianza pubblicitaria sul Web; l’eliminazione graduale dei cookie di tracciamento e di altri identificatori persistenti di terze parti è attesa da tempo. Tuttavia, mentre i fondamenti dell’industria pubblicitaria stanno cambiando, i suoi maggiori attori sono determinati a restare in piedi.
Google sta guidando la carica per sostituire i cookie di terze parti con un nuovo gruppo di tecnologie «pensate» per indirizzare gli annunci sul Web. E alcune delle sue proposte mostrano che non ha imparato le giuste lezioni dal contraccolpo in atto sul modello del business della sorveglianza. Questo post si concentrerà su una di queste proposte, Federated Learning of Cohorts (FLoC), che è forse la più ambiziosa e potenzialmente la più dannosa.
FLoC vuole essere un nuovo metodo per che il tuo browser esegua la profilazione che i tracker di terze parti erano soliti fare da soli: in questo caso, riducendo la tua attività di navigazione recente ad una etichetta comportamentale per poi condividerla con siti web e inserzionisti. La tecnologia eviterà i rischi per la privacy dei cookie di terze parti, ma ne creerà di nuovi nel processo. Può anche esacerbare molti dei peggiori problemi non legati privacy degli annunci comportamentali, tra cui la discriminazione e il targeting predatorio.
L’assist di Google per i sostenitori della privacy è che un mondo con FLoC (e altri elementi della “sandbox della privacy”) sarà migliore del mondo che abbiamo oggi, dove i data broker e i giganti della tecnologia pubblicitaria tracciano e profilano impunemente. Ma quella cornice si basa sulla falsa premessa che si debba scegliere tra “vecchio tracciamento” e “nuovo tracciamento”. Non è o l’uno o l’altro. Invece di reinventare la ruota del tracciamento, dovremmo immaginare un mondo migliore senza la miriade di problemi degli annunci mirati.
Siamo a un bivio. Dietro di noi c’è l’era dei cookie di terze parti, forse il più grande errore del Web. Davanti a noi ci sono due possibili «scenari di» futuro.
In uno, gli utenti possono decidere quali informazioni condividere con ogni sito con cui scelgono di interagire. Nessuno deve preoccuparsi che la propria navigazione passata venga utilizzata contro di lui o sfruttata per manipolarlo quando aprirà una nuova scheda.
Nell’altro, il comportamento di ogni utente lo segue di sito in sito come una etichetta, invisibile all’apparenza ma ricca di significato per chi sa «dove guardare». La loro cronologia recente, distillata in pochi bit, è “democratizzata” e condivisa con decine di attori anonimi che concorrono al contenuto di ogni pagina web. Gli utenti iniziano ogni interazione con una confessione: ecco cosa ho combinato questa settimana, per favore trattami di conseguenza.
Utenti e sostenitori devono rifiutare FLoC e altri tentativi fuorvianti di reinventare il targeting comportamentale. Imploriamo Google di abbandonare FLoC e reindirizzare i suoi sforzi verso la creazione di un Web veramente a misura di utente.
Cos’è FLoC?
Nel 2019, Google ha presentato Privacy Sandbox , la sua visione per il futuro della privacy sul Web. Al centro del progetto c’è una gamma di protocolli senza cookie progettati per soddisfare la miriade di applicazioni concrete che i cookie di terze parti attualmente forniscono agli inserzionisti. Google ha portato le sue proposte al W3C, l’ente di definizione degli standard per il Web, dove sono state discusse principalmente all’interno del Web Advertising Business Group, un organismo composto principalmente da fornitori di tecnologia pubblicitaria. Nei mesi successivi, Google e altri inserzionisti hanno proposto decine di norme tecniche con nomi a tema “uccelli”: PIGIN, TURTLEDOVE, SPARROW, SWAN, SPURFOWL, PELICAN, PARROT… l’elenco potrebbe continuare. Sul serio. Ciascuna delle proposte “uccello” è progettata per svolgere nell’ecosistema della pubblicità mirata una delle funzioni che è attualmente svolta dai cookie.
FLoC è progettato per aiutare gli inserzionisti a eseguire il targeting comportamentale senza cookie di terze parti. Un browser con FLoC abilitato raccoglie informazioni sulle abitudini di navigazione dell’utente, quindi le utilizza per assegnare l’utente a una “coorte” o gruppo. Gli utenti con abitudini di navigazione simili, per una qualsiasi definizione di “simile”, verrebbero raggruppati nella stessa coorte. Il browser di ogni utente condividerà un ID «identificatore» di coorte, indicante a quale gruppo appartiene, con siti web e inserzionisti. Secondo la proposta, almeno qualche migliaio di utenti dovrebbero appartenere a ciascuna coorte (anche se non è una garanzia).
Se sembra oscuro, pensaci in questo modo: il tuo identificatore FLoC sarà come un breve riassunto della tua attività recente sul Web.
Una dimostrazione di esempio di Google ha impiegato i domini dei siti visitati da ciascun utente come base per raggruppare le persone. Ha quindi utilizzato un algoritmo chiamato SimHash per creare i gruppi. SimHash può essere calcolato localmente sulla macchina di ogni utente, quindi non è necessario un server centrale per raccogliere dati comportamentali. Tuttavia, un amministratore centrale potrebbe avere un ruolo nell’applicazione di garanzie sulla privacy. Per evitare che qualsiasi coorte sia troppo piccola (cioè troppo identificativa), Google propone che un soggetto centrale possa contare il numero di utenti assegnati a ciascuna coorte. Se alcune risultassero troppo piccole, potrebbero essere combinate con altre coorti simili fino a raggiungere un numero sufficiente di utenti in ciascuna di esse.
Stando alla proposta, la maggior parte delle specifiche sono ancora da definire. La bozza delle specifiche afferma che l’identificatore di coorte di un utente sarà disponibile tramite Javascript, ma non è chiaro se ci saranno restrizioni su chi può accedervi o se l’ID sarà condiviso in altri modi. FLoC potrebbe eseguire il raggruppamento in base agli URL o al contenuto della pagina invece che ai domini; potrebbe anche utilizzare un sistema basato sull’apprendimento federato (come suggerisce il nome FLoC) per generare i gruppi in alternativa a SimHash. Inoltre, non è chiaro esattamente quante possibili coorti ci saranno. L’esperimento di Google ha utilizzato identificatori di coorte a 8 bit, il che significa che c’erano solo 256 coorti possibili. In pratica quel numero potrebbe essere molto più alto; la documentazione suggerisce un identificatore di coorte a 16 bit composto da 4 caratteri esadecimali. Più coorti sono previste, più specifiche risulteranno; identificatori di coorte più lunghi significa che gli inserzionisti impareranno di più sugli interessi di ogni utente e saranno facilitati nel fingerprinting.
Un elemento che è specificato è la durata. Le coorti FLoC verranno ricalcolate su base settimanale, ogni volta utilizzando i dati della navigazione della settimana precedente. Ciò rende le coorti FLoC meno utili come identificatori a lungo termine, ma li rende anche misurazioni più efficaci di come gli utenti si comportano nel tempo.
Nuovi problemi di privacy
FLoC fa parte di un insieme inteso a portare gli annunci mirati in un futuro che preservi la privacy. Ma il suo concetto base prevede la condivisione di nuove informazioni con gli inserzionisti. Non sorprende che questo crei anche nuovi rischi per la privacy.
Fingerprinting
Il primo problema è il fingerprinting. Il fingerprinting del browser è la pratica di raccogliere molte informazioni discrete dal browser di un utente per creare un identificatore univoco e stabile per quel browser. Il progetto Cover Your Tracks di EFF dimostra come funziona il processo: in breve, più il tuo browser appare o si comporta in modo diverso da quello degli altri, più facile è il fingerprinting.
Google ha promesso che la stragrande maggioranza delle coorti FLoC comprenderà migliaia di utenti ciascuna, quindi un identificatore di coorte da solo non dovrebbe distinguerti da alcune migliaia di altre persone come te. Tuttavia, ciò offre ancora al fingerprinting un enorme vantaggio. Se un tracker inizia dalla tua coorte FLoC, deve solo distinguere il tuo browser da poche migliaia di altri (piuttosto che da alcune centinaia di milioni). In termini di teoria dell’informazione, le coorti FLoC conterranno diversi bit di entropia, fino a 8 bit, nella prova dimostrativa di Google. Questa informazione è ancora più potente dato che è improbabile che sia correlata con altre informazioni che il browser espone. Ciò renderà molto più facile per i tracker mettere insieme un fingerprinting unico per gli utenti FLoC.
Google ha riconosciuto questa come una sfida, ma si è impegnata a risolverla come parte del più ampio piano “Privacy Budget” che porta avanti per affrontare il fingerprinting nel lungo termine. Risolvere il fingerprinting è un obiettivo ammirevole e la sua proposta è una strada promettente da perseguire. Ma secondo le FAQ, quel piano è “una proposta in una fase iniziale e non ha ancora un’implementazione del browser”. Nel frattempo, Google inizierà a testare FLoC già questo mese .
Il fingerprinting è notoriamente difficile da fermare. Browser come Safari e Tor si sono impegnati in lunghe battaglie contro i tracker, sacrificando ampie parti dei propri set di funzionalità al fine di ridurre le superfici di attacco al fingerprinting. La mitigazione del fingerprinting generalmente implica l’eliminazione o la limitazione di elementi di entropia non necessarii, che è ciò che «invece» è FLoC. Google non dovrebbe creare nuovi rischi relativi al fingerprinting fino a quando non avrà capito come affrontare quelli esistenti.
Esposizione cross-context
Il secondo problema è meno semplice dal spiegare: la tecnologia condividerà nuovi dati personali con i tracker che possono già identificare gli utenti. Affinché FLoC sia utile agli inserzionisti, la coorte di un utente rivelerà necessariamente informazioni sul proprio comportamento.
La pagina Github del progetto affronta questo problema in anticipo:
This API democratizes access to some information about an individual’s general browsing history (and thus, general interests) to any site that opts into it. … Sites that know a person’s PII (e.g., when people sign in using their email address) could record and reveal their cohort. This means that information about an individual’s interests may eventually become public.
Come descritto sopra, le coorti FLoC non dovrebbero da sole funzionare come identificatori. Tuttavia, qualsiasi azienda in grado di identificare un utente in altri modi, ad esempio offrendo servizi tramite “Accedi con Google” ai siti su Internet, sarà in grado di collegare le informazioni apprese da FLoC al profilo dell’utente.
Due categorie di informazioni possono essere esposte in questo modo:
1.Informazioni specifiche sulla cronologia di navigazione. I tracker possono essere in grado di decodificare l’algoritmo di assegnazione ad una coorte per determinare che qualsiasi utente che appartiene a quella coorte specifica probabilmente o sicuramente ha visitato siti specifici.
2. Informazioni generali su dati demografici o interessi. Gli osservatori possono apprendere che, in generale, è molto probabile che membri di una specifica coorte appartengano ad uno specifico tipo di persona. Ad esempio, una particolare coorte può sovrarappresentare gli utenti giovani, le donne e i neri; un’altra coorte, gli elettori repubblicani di mezza età; una terza, i giovani LGBTQ+.
Questo significa che ogni sito che visiti avrà una buona idea di che tipo di persona sei già al primo contatto, senza dover fare il lavoro di tracciarti attraverso il web. Inoltre, poiché la tua coorte FLoC si aggiornerà nel tempo, i siti che possono identificarti in altri modi saranno anche in grado di monitorare come cambia la tua navigazione. Ricorda, una coorte FLoC non è niente di più e niente di meno che un riassunto della tua recente attività di navigazione.
Dovresti avere il diritto di presentare diversi aspetti della tua identità in diversi contesti. Se visiti un sito per informazioni mediche, potresti affidargli informazioni sulla tua salute, ma non c’è motivo per cui debba conoscere qual è la tua collocazione politica. Allo stesso modo, se visiti un negozio online, «questo» non dovrebbe aver bisogno di sapere se recentemente hai letto di trattamenti per la depressione. FLoC erode questa separazione di contesti e presenta invece lo stesso riassunto comportamentale a tutti coloro con cui interagisci.
Oltre la privacy
FLoC è progettato per prevenire una minaccia molto specifica: il tipo di profilazione individuale che attualmente è consentita dagli identificatori cross-context. L’obiettivo di FLoC e di altre proposte è evitare che i tracker possano accedere a informazioni specifiche riconducibili a persone specifiche. Come abbiamo mostrato, FLoC può effettivamente aiutare i tracker in molti contesti. Ma anche se Google è in grado di rafforzare il suo progetto e prevenire questi rischi, i danni della pubblicità mirata non si limitano alle violazioni della privacy. L’obiettivo principale di FLoC è in contrasto con altre libertà civili.
Il potere di puntare è il potere di discriminare. Per definizione, gli annunci mirati consentono agli inserzionisti di raggiungere alcuni tipi di persone escludendone altri. Un sistema di targeting può essere utilizzato per decidere chi può vedere annunci di lavoro o offerte di prestito con la stessa facilità con cui pubblicizza scarpe.
Negli anni, il meccanismo della pubblicità mirata è stato spesso utilizzato per lo sfruttamento, la discriminazione e il nocumento. La possibilità di indirizzare gli annunci alle persone in base all’etnia, alla religione, al sesso, all’età o alle capacità consente annunci discriminatori per lavoro, alloggio e credito. Il targeting basato sulla storia del credito, o sulle caratteristiche sistematicamente associate ad esso, consente annunci predatori per prestiti ad alto interesse. Il targeting basato su dati demografici, posizione e affiliazione politica aiuta chi diffonde disinformazione politica e la disaffezione degli elettori. Tutti i tipi di targeting comportamentale aumentano il rischio di truffe credibili.
Google, Facebook e molte altre piattaforme pubblicitarie cercano già di frenare determinati usi delle proprie piattaforme di targeting. Google, ad esempio, limita la capacità degli inserzionisti di indirizzare gli annunci a persone in “categorie di interessi sensibili”. Tuttavia, questi sforzi spesso falliscono; attori determinati possono solitamente trovare soluzioni alternative alle restrizioni a livello di piattaforma su determinati tipi di targeting o determinati tipi di annunci.
Anche con un potere assoluto su quali informazioni possono essere utilizzate per indirizzare chi, le piattaforme sono troppo spesso incapaci di impedire l’abuso della loro tecnologia. Ma FLoC utilizzerà un algoritmo non supervisionato per creare i suoi raggruppamenti. Ciò significa che nessuno avrà il controllo diretto sul modo in cui le persone sono raggruppate. Idealmente (per gli inserzionisti), FLoC creerà gruppi che hanno comportamenti e interessi significativi in comune. Ma il comportamento online è collegato a tutte le caratteristiche sensibili: dati demografici come sesso, etnia, età e reddito; Tratti della personalità “big 5”; anche la salute mentale . È molto probabile che FLoC raggrupperà anche gli utenti lungo alcuni di questi assi. I raggruppamenti di FLoC possono anche riflettere direttamente le visite a siti Web relativi ad abuso di sostanze, difficoltà finanziarie o supporto per i sopravvissuti a traumi.
Google ha proposto di poter monitorare gli output del sistema per verificare eventuali correlazioni con le sue categorie sensibili. Se rileva che una particolare coorte è troppo strettamente correlata a un particolare gruppo protetto, il server amministrativo può scegliere nuovi parametri per l’algoritmo e dire ai browser degli utenti di raggrupparsi di nuovo.
Questa soluzione suona sia orwelliana che sisifea. Per monitorare il modo in cui i gruppi di FLoC sono correlati alle categorie sensibili, Google dovrà eseguire controlli massicci utilizzando dati su razza, sesso, religione, età, salute e situazione finanziaria degli utenti. Ogni volta che trova una coorte che si correla troppo fortemente lungo uno qualsiasi di questi assi, dovrà riconfigurare l’intero algoritmo e riprovare, sperando che nella nuova iterazione non siano implicate altre “categorie sensibili”. Questa è una variante molto più complessa del problema che sta già tentando, spesso senza riuscirci, di risolvere.
In un mondo con FLoC, potrebbe essere più difficile indirizzare gli utenti direttamente in base all’età, al sesso o al reddito. Ma non sarà impossibile. I tracker con accesso a informazioni ausiliarie sugli utenti saranno in grado di apprendere cosa “significano” i raggruppamenti FLoC e che tipo di persone contengono, attraverso l’osservazione e la sperimentazione. Coloro che sono determinati a farlo saranno comunque in grado di discriminare. Inoltre, questo tipo di comportamento sarà più difficile da controllare per le piattaforme di quanto non lo sia già. Gli inserzionisti con cattive intenzioni avranno una negazione plausibile: dopo tutto, non prendono direttamente di mira le categorie protette, ma raggiungono le persone in base al comportamento. E l’intero sistema sarà più opaco per utenti e regolatori.
Google, per favore non farlo
Abbiamo scritto di FLoC e dell’altro gruppo iniziale di proposte quando sono state introdotte per la prima volta, definendo FLoC “l’opposto della tecnologia per la tutela della privacy”. Speravamo che il processo di standardizzazione avrebbe fatto luce sui difetti fondamentali di FLoC, inducendo Google a riconsiderare la possibilità di portarlo avanti. In effetti, diversi problemi sulla pagina ufficiale Github sollevano le stesse esatte preoccupazioni che abbiamo evidenziato qui. Tuttavia, Google ha continuato a sviluppare il sistema, lasciandone i fondamentali quasi invariati. Ha iniziato a proporre FLoC agli inserzionisti, vantandosi che FLoC è un sostituto “efficace al 95%” del targeting basato sui cookie. E a partire da Chrome 89, rilasciato il 2 marzo, sta distribuendo la tecnologia per una prima prova . Una piccola parte degli utenti di Chrome, probabilmente milioni di persone, sarà (o è stata) assegnata a testare la nuova tecnologia.
Non fate errori, se Google porterà a termine il suo piano per introdurre FLoC in Chrome, probabilmente darà ai soggetti coinvolti delle “opzioni”. Il sistema sarà probabilmente opt-in per gli inserzionisti che ne beneficeranno e opt-out per gli utenti che rischiano di essere danneggiati. Google lo pubblicizzerà sicuramente come un passo avanti per la “trasparenza e il controllo all’utente”, sapendo benissimo che la stragrande maggioranza dei suoi utenti non capirà come funziona FLoC e che pochissimi faranno di tutto per disattivarlo. Si darà una pacca sulla spalla per aver inaugurato una nuova era privata sul Web, libera dal malvagio cookie di terze parti, la «stessa» tecnologia che Google ha contribuito ad estendere ben oltre la sua durata di conservazione, guadagnando miliardi di dollari nel processo .
Non deve essere così. Le parti più importanti della sandbox per la privacy, come l’eliminazione di identificatori di terze parti e la lotta fingerprinting, cambieranno davvero il Web in meglio. Google può scegliere di smantellare la vecchia impalcatura per la sorveglianza senza sostituirla con qualcosa di nuovo e unicamente dannoso.
Rifiutiamo decisamente il futuro di FLoC. Questo non è il mondo che vogliamo, né quello che gli utenti meritano. Google ha bisogno di imparare le giuste lezioni dall’era del monitoraggio di terze parti e progettare il suo browser in modo che lavori per gli utenti, non per gli inserzionisti.
![]()
La restaurazione del CLOUD




Da:
Cyber bluff
di Ginox
Utilizziamo internet per qualsiasi cosa: informarci, acquistare, studiare, divertirci, comunicare. Spesso ci sembra impossibile distinguere la rete dal servizio che si utilizza: il web è Google, Instagram, Facebook. Sono poche le persone che si interrogano sulla rete a cui questi servizi si appoggiano per capire da dove viene, com’è nata e da chi è controllata. Sappiamo come funziona questo strumento, questa rete che è onnipresente nelle nostre vite? Sappiamo dove vanno i nostri dati e chi ne trae profitto? Abbiamo davvero bisogno di comunicazioni istantanee? Internet è davvero democratico? Questo libro descrive i servizi online più diffusi, raccontandone la genesi, il funzionamento, e fornendo alcuni consigli utili per utilizzarli in maniera più consapevole.
Utilizzando il QR code all’interno del libro è possibile inoltre scaricare un documento di approfondimento con schede e consigli tecnici.

Fediverso: decentralizzazione vs “sala dei bottoni”
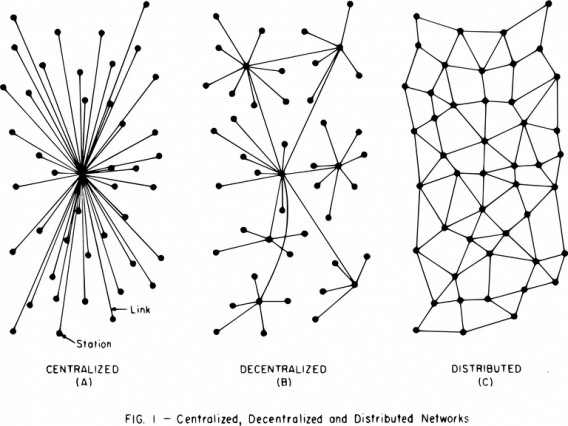
E’ possibile creare un social network autogestito?
E se i social network fossero piú di uno, federabili tra loro?
Il Fediverso (Federazione + Universo)
Il Fediverso è una rete di server federati che viene utilizzata per una serie di attività parallele, assimilabili a quelle dei social-network come: piattaforme per blog, ospitare e condivisione dei file… Una specie di rete di social-network che vuole essere in qualche modo alternativa ai social-network commerciali più famosi.
Quello che distingue il Fediverso è che, innanzitutto i progetti che lo compongono, le piattaforme che ne fanno parte, federandosi appunto tra di loro, sono basate su protocolli aperti. Il più famoso è ArctivityPub, protocolli aperti rilasciati come software libero che può essere modificato da chi lo utilizza. Anche per il software delle piattaforme del Fediverso viene utilizzato software libero.
Una differenza importante tra i social commerciali e il Fediverso è che se ad esempio apro un account su Twitter devo stare alle regole del social che sono valide, uguali per tuttə. Mentre se apro un account nel Fediverso per esempio su Mastodon, una innovativa piattaforma di microblogging open source le cui funzionalità possono ricordare Twitter o Tumblr, non esiste una policy unica per tuttə gli utenti ma esistono dei server più piccoli che si chiamano Istanze ognuna delle quali ha una propria policy. Posso scegliere di registrare un account quindi affidare i miei dati ed essere espostə a un certo tipo di contenuti nel server dell’Istanza che più corrisponde ai miei bisogni, valori, interessi anche politici, a quello che voglio cercare, fare, su un social network.
Un altro esempio è stereodon.social se sei interessato di musica. arte ecc. Nel Fediverso trovi PeerTube simile a youtube.
Non c’è un social network chiamato Mastodon! Ci sono, invece, migliaia di social network indipendenti chiamati Istanze Mastodon.
Mastodon è parte di un qualcosa di più ampio chiamato Fediverso (Federazione + Universo).
Quest’immagini, possono fornire un’idea del modo in cui le Istanze (pianeti) si connettono tra loro. Se poi si considera che le Istanze del Fediverso conosciute sono migliaia, la complessità del quadro è ben immaginabile.
Su Kum.io é possibile trovare una rappresentazione interattiva del Fediverso così come appare al momento.
Il tutto con una tecnologia aperta e gestibile da chiunque, senza un’unica centrale operativa o “stanza dei bottoni”. Parlare lo stesso linguaggio allarga i confini della convivialità.
 In sostanza più si interagisce con persone che stanno su altre Istanze e più grande diventa il network della propria Istanza, fino al punto da formare un gigantesco network federato composto da un numero enorme di Istanze indipendenti. Il network federato della tua Istanza probabilmente non coprirà mai l’intera Galassia Mastodon ma solo una sua parte. Quanto si estenderà dipende da quanto sono attive le persone sulla tua Istanza: più connessioni creerete con Istanze diverse e lontane e più grande sarà il vostro network.
In sostanza più si interagisce con persone che stanno su altre Istanze e più grande diventa il network della propria Istanza, fino al punto da formare un gigantesco network federato composto da un numero enorme di Istanze indipendenti. Il network federato della tua Istanza probabilmente non coprirà mai l’intera Galassia Mastodon ma solo una sua parte. Quanto si estenderà dipende da quanto sono attive le persone sulla tua Istanza: più connessioni creerete con Istanze diverse e lontane e più grande sarà il vostro network.

Per approfondire:
La migliore guida su mastodon in italiano:
https://mastodon.help/it
Il manifesto dell’istanza mastodon bida:
https://mastodon.bida.im/about/more#italiano
Il report per i 3 anni di bida:
https://bida.im/press.html#bidatreannidopo
Manifesto minimo per un fediverso autogestito:
https://autogestione.social/
Per registrare un account:
https://mastodon.bida.im/

Meglio di Zoom e Google Meet: prova queste app e servizi di videoconferenza implementati con software libero
![]()
Meglio di Zoom e Google Meet: prova queste app e servizi di videoconferenza implementati con software libero
Per le videoconferenze ti consigliamo di usare software libero come Jitsi e BigBlueButton. Sono software liberi, quindi il software è sotto il controllo dell’utente, danno all’utente la libertà di gestire il proprio server e il pieno controllo delle loro comunicazioni.
È del tutto possibile gestire online grandi conferenze usando software libero. La FSF ha ospitato il suo annuale LibrePlanet 2020 e l’evento per il 35° anniversario della FSF tutto online usando software libero e hardware RYF. La conferenza LibrePlanet dal 2014 è stata trasmessa in live streaming ad un pubblico mondiale. FOSDEM 2021 è stato ospitato online con un pubblico di oltre 30.000 persone utilizzando esclusivamente software libero.
Problemi con i sistemi di videoconferenza proprietari
I sistemi di videoconferenza come Zoom e Google Meet richiedono che gli utenti usino programmi client proprietari. Questa è una sostanziale prevazicazione nei confronti dell’utente perché qualsiasi software non libero toglie agli utenti la libertà di controllare quel programma.
Inoltre, le comunicazioni video con il software propietario Zoom hanno luogo attraverso il server centrale di Zoom. La combinazione di software non libero del client e del server centrale dà a Zoom il potere sugli utenti che utilizza per spiarli, censurando i dissidenti e impedendo a certi gruppi di connettersi al suo servizio.
La sorveglianza e la censura sono le conseguenze del potere che Zoom ha sui suoi utenti risultato del suo software non libero e del server centralizzato. È al potere ingiusto di Zoom sui suoi utenti che ci opponiamo. Questo potere porta gli utenti ad essere in balia dell’entità (Zoom in questo caso) che fornisce il servizio. Lo stesso vale per altri sistemi di video conferenza non liberi come Google Meet, Microsoft Teams, Skype, ecc.
Per quanto riguarda la privacy non ci si dovrebbe mai fidare dei programmi non liberi anche se dicono che le comunicazioni sono criptate end-to-end. Potrebbero inviare la versione non criptata al proprietario del software quando li viene chiesto, bypassando la crittografia. Una società che vendeva sistemi di crittografia a 100 paesi era controllata dall’intelligence statunitense e tedesca e l’apparecchiatura spiava i governi che la usavano, il che significa che non dovreste mai fidarvi di un programma di crittografia proprietario per proteggere la vostra privacy. Pertanto, vi suggeriamo di rifiutare qualsiasi software non libero/proprietario.
In che modo i sistemi di videoconferenza basati su software libero possono risolvere il problema?
Se gli utenti comunicano usando software libero installato su un server controllato dagli utenti o su di un server gestito da un fornitore di servizi fidato, ottengono il pieno controllo delle loro comunicazioni. Questo dà loro il controllo sulle politiche del servizio e sulla raccolta dei dati. Con software libero come Jitsi e BigBlueButton, hai una scelta di fornitori di servizi e non sei costretto a ospitare le tue riunioni video su un determinato server, diciamo, il server centrale di Jitsi. Puoi anche ospitare il servizio in paesi con leggi migliori sulla libertà di parola invece di essere costretto a seguire solo la legge cinese, nel caso di Zoom. È come se i dissidenti si rifugiassero in altri paesi per evitare persecuzioni da parte di governi oppressivi.
Le istanze Jitsi di solito hanno una capacità massima di 70 partecipanti alla volta. Un elenco di istanze Jitsi è disponibile qui https://jitsi.github.io/handbook/docs/community/community-instances e un elenco di istanze BigBlueButton è disponibile qui https://wiki.chatons.org/doku.php/la_visio-conference_avec_big_blue_button. Non abbiamo provato tutte le istanze elencate in questi link, questo è solo un elenco per gli utenti per provare istanze diverse. Ti consigliamo di leggere le politiche dei server prima di ospitarvi le tue comunicazioni.
L’istanza Jitsi di Autistici https://vc.autistici.org/ supporta la registrazione senza utilizzare Dropbox o qualsiasi altro servizio di software non libero (altre istanze Jitsi di solito richiedono un account Dropbox) e il live-stream senza utilizzare YouTube (altri servizi di solito supportano il live-streaming solo con YouTube) sul proprio server. Per registrare la riunione sul server di Autsitici, è possibile fare clic su ‘Avvia registrazione’ quando si desidera avviare e poi ‘Interrompi registrazione’. Ti verrà inviato un collegamento nella chat Jitsi e potrai scaricare la registrazione sul tuo dispositivo.
Le istanze di Jitsi come 8×8.vc hanno un numero indiano (non un numero verde ma un numero a Mumbai) per partecipare all’audio conferenza. Così anche le persone che hanno un tempo di conversazione illimitato ma non una buona connessione internet possono unirsi.
tube.tchncs.de e altre istanze di PeerTube che supportano il live-streaming possono essere un’altra opzione. joinpeertube.org/instances ha una lista di istanze di PeerTube e puoi filtrare la lista scegliendo il profilo ‘Video maker’ e ‘Yes’ all’opzione ‘And do live streams’. App come NewPipe e Fedilab supportano la visione di video PeerTube e live stream. OBS può essere usato per trasmettere le lezioni in diretta.
Le istanze di BigBlueButton hanno in genere una capacità maggiore rispetto alle istanze Jitsi e istanze come meet.nixnet.services possono arrivare fino a 270+. L’approccio misto del live streaming e l’utilizzo di chat di testo separate per le domande possono aumentare i limiti dei partecipanti. BigBlueButton supporta la lavagna, presentazioni, live streaming su YouTube. Ti consigliamo di evitare la diretta streaming su YouTube. BigBlueButton non ha bisogno di alcuna app sui cellulari per funzionare, le persone possono semplicemente partecipare tramite qualsiasi browser web.
Conferenze usando solo software libero
Nel periodo pandemico, abbiamo visto organizzare con successo conferenze anche usando solo software libero. FSCI e Free Software Foundation of India hanno condotto il Free Software Camp FreeSoftware Camp interamente usando Big Blue Button . Anche le conferenze DebConf e MiniDebConf Online India 2021 sono state tenute usando Jitsi e Vogol per il live-streaming delle conferenze e Etherpad + chat IRC sono stati usati dal pubblico per fare domande. La Free Software Foundation Free Software Foundation ha condotto la sua conferenza annuale LibrePlanet 2020 online senza l’uso di alcun sofware non libero/propietario. La conferenza FOSDEM 2021 è stata condotta utilizzando solo software libero e ha ospitato 30.000 partecipanti, il che dimostra che non c’è assolutamente motivo per cui qualsiasi conferenza online debba richiedere software proprietario. Qualsiasi organizzazione che voglia organizzare una conferenza può assumere le proprie persone o assumere alcune delle persone che hanno organizzato il FOSDEM per implementare la tecnologia per voi. Se possono ospitare la loro conferenza usando solo software libero, anche altre organizzazioni possono farlo.
Gli istituti scolastici dovrebbero passare al software libero
Consigliamo agli istituti scolastici di adottare alternative di software libero come Jitsi, BigBlueButton ed evitare il software propietario/non libero per lezioni e videoconferenze.
I casi d’uso educativi per BigBlueButton sono
Tutoraggio online (uno a uno)
Flipped classrooms/Insegnamento capovolto (registrazione dei contenuti prima della sessione)
Collaborazione di gruppo (molti a molti)
Lezioni online (uno-a-molti)
Gli insegnanti possono coinvolgere gli studenti in remoto con sondaggi, emoji, lavagna interattiva e articolarli in sale minori/breakout rooms. I relatori possono registrare e riprodurre contenuti per poi condividerli con gli altri.
Chiguru gestisce anche un server BigBlueButton soprattutto per le lezioni online e include piani a pagamento secondo le tue necessità. Le conferenze possono essere tenute utilizzando solo software libero simile alle conferenze di cui sopra. Gli istituti scolastici hanno la responsabilità nei confronti dei loro studenti e insegnanti di rispettare la loro libertà e privacy. Gli studenti non dovrebbero essere costretti a rinunciare alla loro libertà e privacy per frequentare le lezioni, webinar per costruire la loro carriera.
Esortiamo gli insegnanti ad aiutare i loro studenti a resistere a Zoom o ad altri software proprietari per l’insegnamento online.
Modi in cui gli studenti possono resistere
Per dimostrare il rifiuto del software non libero, gli studenti possono resistere in vari modi. Gli studenti possono mettersi in contatto tra loro e inviare lettere collettive agli insegnanti o alla loro amministrazione per creare consapevolezza sui problemi che il software proprietario pone. Per aumentare la consapevolezza, possono condividere questo articolo. Possono chiedere ai loro insegnanti di fare registrazioni delle chiamate Zoom e pubblicare le registrazioni dove loro possano scaricarle in seguito. Suggeriamo un software libero come https://upload.disroot.org/ o PeerTube per condividere le lezioni video.
Gli studenti possono anche impostare degli espedienti per evitare di usare programmi di video chat non liberi. Per esempio, l’insegnante (o uno studente) potrebbe puntare una telecamera su uno schermo che mostra la chiamata di Zoom, e trasmettere in streaming la telecamera e il microfono agli studenti che vogliono rimanere fuori da Zoom. Si può anche usare un espediente per parlarsi e inviare la voce alla chiamata di Zoom.
Come iniziare e partecipare a una riunione tramite Jitsi e BigBlueButton?
Trova un servizio Jitsi adatto alle tue esigenze e crea una stanza con un nome casuale o un nome che puoi ricordare. Condividi il link della riunione con i partecipanti. Partecipare a un meeting Jitsi è facile come cliccare su un link e caricarlo nel tuo browser (versioni recenti di Chromium e Firefox) o nelle app Jitsi Meet per Android o iOS e non è richiesta la creazione di alcun account. Le riunioni di Jitsi possono anche essere protette da password in modo che solo i partecipanti invitati possano partecipare.
Trova un’istanza di BigBlueButton che si adatta alle tue esigenze e registra un account. Una volta effettuato l’accesso, è possibile creare stanze e condividere i link con i partecipanti. Partecipare ad un meeting BigBlueButton è facile come cliccare su un link e caricarlo nel vostro browser (versioni recenti di Chromium e Firefox) sia sul vostro laptop/desktop che sul tuo cellulare.
Meglio di WhatsApp: Prova queste applicazioni e servizi di software libero
![]()
Meglio di WhatsApp: Prova queste applicazioni e servizi di software libero
Consigliamo di usare app di software libero come Element, Quicksy o Conversations che si collegano a servizi basati su software libero. Questi servizi permettono agli utenti di scegliere il loro fornitore senza perdere la possibilità di parlare con gli utenti di altri fornitori che seguono lo stesso standard. Il software libero assicura la libertà degli utenti e i servizi interoperabili assicurano che non ci sia alcun vendor lock-in (vincolo del fornitore).
Qualsiasi app non libera controlla l’utente, mentre le app con software libero sono controllata dai suoi utenti. Quando si parla di software libero, free software, non si parla del prezzo, ma di libertà.
Confronto tra diverse app e servizi
1 – Client e server non-free software + centralizzazione (Esempio WhatsApp): non rispetta la libertà dell’utente e crea vendor lock-in/vincolo del fornitore.
2 – Client di software libero ma server non libero + centralizzazione (Esempio Telegram): il software client rispetta la libertà, il software server non rispetta la libertà e crea vendor lock-in.
3 – Software libero client e server + centralizzazione (Esempio Signal): rispetta la libertà dell’utente ma crea il vendor lock-in.
4 – Software libero client e server + federazione (Esempio Matrix e Quicksy/XMPP): rispetta la libertà dell’utente (come utente o come comunità) e non crea vendor lock-in.
5 – Client di software libero + design peer to peer (Esempio Briar, Tox): rispetta la libertà degli utenti e nessun vendor lock-in.
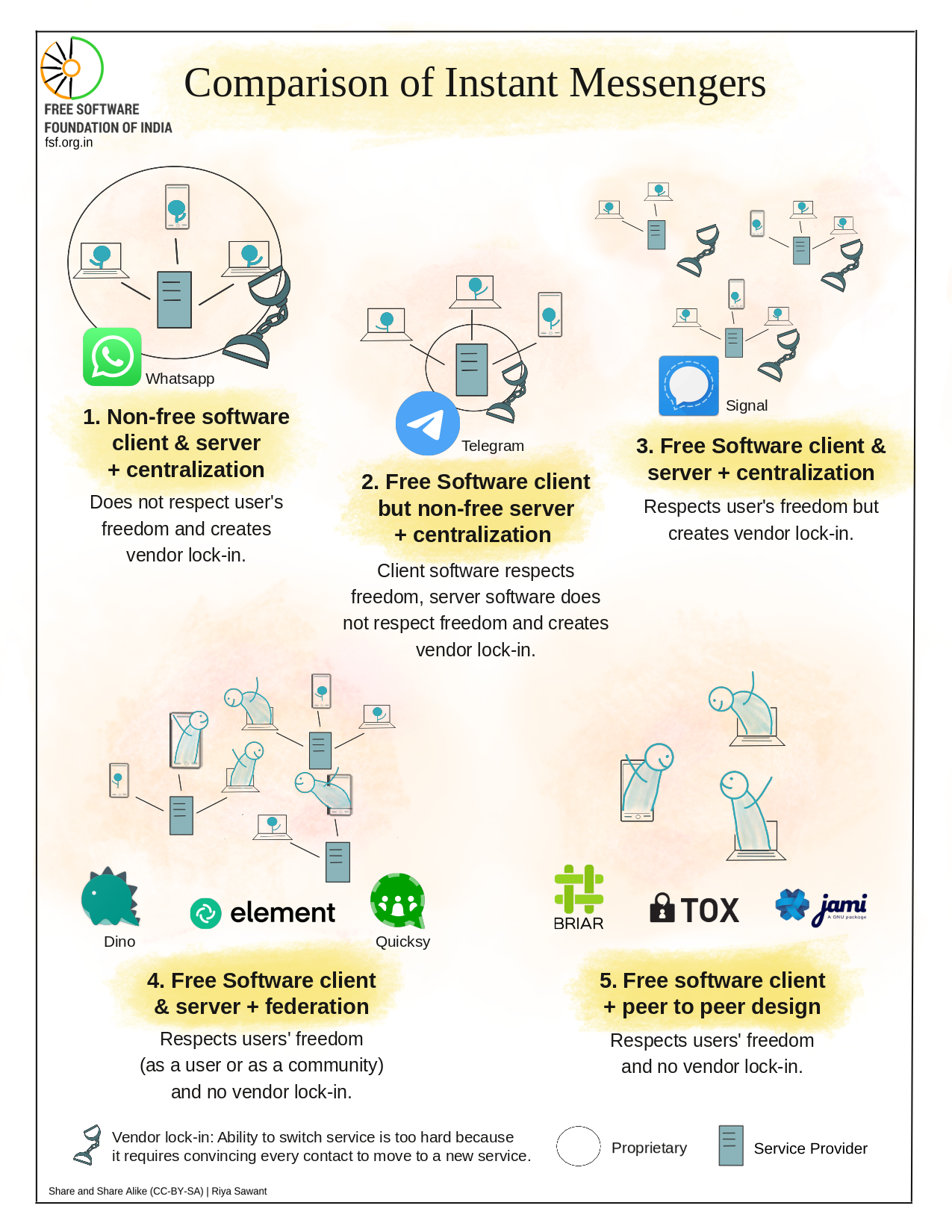
Alcuni concetti di base
Vendor lock-in: il cliente non dispone delle competenze e delle informazioni sufficienti per poter acquistare determinati beni o servizi da un fornitore differente con costi e rischi sostenibili.
Design Peer-to-Peer : design che permette a un utente di comunicare direttamente con un altro utente senza coinvolgere alcun fornitore di servizi nel mezzo. Entrambe le parti devono essere online allo stesso tempo perché il design funzioni in modo efficiente.
Crittografia End-to-End : solo gli utenti che partecipano a una comunicazione possono leggere i messaggi.
WhatsApp e altre app non libere
L’app WhatsApp è un software non libero che non rispetta la libertà e la privacy dell’utente. WhatsApp non fornisce ai suoi utenti l’accesso al suo codice sorgente e vieta energicamente a chiunque crei un’applicazione con software libero di poter connettersi al servizio WhatsApp. Sostengono che la loro app fornisce la crittografia end-to-end, ma non possiamo verificare se hanno effettivamente implementato la crittografia end-to-end senza alcuna backdoor (accesso dell’app in remoto senza il permesso dell’utente) o scappatoie. Essendo un’app non libera è sufficiente per rifiutare WhatsApp, quindi non tratteremo gli altri aspetti negativi di WhatsApp.
Esistono tre grandi categorie di sistemi di messaggistica con app di software libero: servizi centralizzati, servizi federati e sistemi peer-to-peer.
A. Servizi centralizzati
Un servizio centralizzato è quello in cui tutti sono costretti ad usare lo stesso fornitore. Configurazioni come questa hanno molti svantaggi come il vendor lock-in dei fornitore, essere più soggetti alle back-door del governo, il mondo intero che dipendente da una singola organizzazione per le loro comunicazioni. I servizi centralizzati hanno anche un Single Point of Failure SPOF (singolo punto di vulnerabilità). L’organizzazione che controlla il servizio può essere venduta a un’altra organizzazione, modificare o addirittura chiudere l’operazione, impostare i propri termini di servizio e la politica sulla privacy, vietare alle app di terze parti di connettersi al servizio centralizzato.
- Telegram
- Pro: Le applicazioni client per Telegram sono software libero.
- Gli utenti IRC e Matrix possono parlare con gli utenti di Telegram attraverso un ponte senza creare un account Telegram.
Contro: Il componente del servizio Telegram – che consente la comunicazione tra gli utenti Telegram – è proprietario (non libero) e non è federato.
La crittografia end-to-end è disponibile solo sulle app di Telegram del cellulare.
È necessario un numero di telefono per iscriversi.
Riepilogo: I client ufficiali di Telegram sono un amalgama di parti libere (come in libertà) e proprietari (non liberi); il componente di servizio Telegram è proprietario al 100%.
Signal
Pro: L’app Signal è Software Libero come Telegram, e rispetto a Telegram offre anche il software del server come Software Libero questo la rende migliore di Telegram.
La crittografia end-to-end è abilitata come impostazione predefinita e anche le chat di gruppo sono crittografate.
Metadati minimi raccolti sul server .
Contro: Anche se ti è permesso configurare il servizio Signal da solo, gli utenti del tuo servizio non saranno in grado di parlare con gli utenti del server Signal ufficiale, rendendolo praticamente un lock-in del fornitore.
Ha bisogno di un numero di telefono per l’iscrizione.
Riepilogo: Signal è meglio di WhatsApp e Telegram.
B. Servizi federati
Un sistema federato è un insieme di fornitori di servizi indipendenti che possono comunicare tra loro. La Federazione è importante per avere il pieno controllo delle proprie comunicazioni. Puoi scegliere un fornitore di fiducia o essere tu stesso un fornitore di servizi. Nessuna singola entità può imporre i propri termini agli utenti. Esempi di sistemi federati sono i telefoni cellulari, le e-mail, matrix, XMPP ecc. Per esempio, puoi comprare una carta SIM da qualsiasi fornitore di servizi mobili e parlare o inviare SMS agli abbonati di altri fornitori. Allo stesso modo, è possibile creare un account di posta elettronica con qualsiasi fornitore di servizi e inviare e-mail a persone che sono registrate con un provider di posta elettronica diverso.
Quicksy
Pro: Federato con XMPP, Controllo delle politiche dei servizi, passare a qualsiasi provider XMPP senza perdere la possibilità di parlare con tutti i tuoi contatti Quicksy.
La crittografia end-to-end è abilitata per impostazione predefinita e anche le chat di gruppo sono crittografate per impostazione predefinita.
Contro: Ha bisogno di un numero di telefono per iscriversi.
Riepilogo: Quicksy è migliore di Signal grazie alla sua progettazione federata.
XMPP tramite app come Conversazioni, Dino
Pro: Oltre a tutti i pro di Quicksy, il numero di telefono / e-mail non è obbligatorio per un account. Se ti auto-ospiti, la conservazione dei metadati è sotto il tuo controllo.
Contro: Il processo di scelta di un fornitore di servizi e la creazione di un account può sembrare difficile poiché potrebbe non esserti familiare, nessun rilevamento automatico dei contatti.
Matrix tramite app come Element, FluffyChat
Pro: Oltre a tutti i pro di XMPP, Matrix chiede il tuo permesso prima di essere aggiunto a una chat personale o a una chat di gruppo.
Contro: Il processo di scelta di un fornitore di servizi e la creazione di un account può sembrare difficile poiché potrebbe non esserti familiare, nessun rilevamento automatico dei contatti.
Riepilogo: XMPP / Matrix è migliore di Quicksy dal punto di vista della privacy e della libertà al costo di un po ‘di scomodità nel creare account e nella ricerca automatica di altri utenti.
Nota: Dato che XMPP/Matrix ti permette di scegliere le app a differenza di quelle accennate sopra, scegli le app che supportano la crittografia end-to-end ( OMEMO per XMPP). Le scelte che abbiamo menzionato hanno la crittografia come impostazione predefinita.
C. Sistemi peer-to-peer (P2P)
I sistemi di messaggistica istantanei peer-to-peer possono parlarsi direttamente senza richiedere alcun server. Esempi sono Briar, Tox e GNU Jami, ecc. I messaggi sono criptati end-to-encrypted e vengono memorizzati solo localmente sui dispositivi poiché non ci sono server coinvolti. Non ci sono server che potrebbero intercettare le tue comunicazioni, quindi ti dà la massima privacy e libertà. Per scambiare messaggi, entrambi i peer devono essere online, il che potrebbe essere un po’ scomodo.
Conclusione
Ti consigliamo di scegliere qualsiasi sistema federato o messenger peer-to-peer in base all’uso che ne fai, in modo da ottenere il pieno controllo delle tue comunicazioni, la libertà e la privacy. È molto importante rifiutare servizi proprietari come WhatsApp che toglie la libertà all’utente.
The “Comparison of Instant Messengers” infographic — Copyright © 2021 Riya Sawant. It is licensed under the Creative Commons Attribution-ShareAlike 4.0 International license.
Schiavitù 2.0 e come evitarla: una guida pratica per cyborg
Schiavitù 2.0 e come evitarla: una guida pratica per cyborg
Un articolo di Aral Balkan
Qui l’originale in inglese : tradotto in tedesco e spagnolo.

– ^ –
Molto probabilmente sei un cyborg e non lo sai nemmeno.
Hai uno smartphone?
Sei un cyborg.
Usi un computer? O il web?
Cyborg!
Più in generale, se usi la tecnologia digitale e in rete oggi, sei un cyborg. Non devi impiantarti dei microchip. Non devi assomigliare a Robocop. Sei un cyborg perché estendi le tue capacità biologiche usando la tecnologia.
Leggendo questa definizione, potresti dire: “Ma aspetta, gli esseri umani lo fanno da molto più tempo di quanto esista la tecnologia digitale”. E avresti ragione.
Eravamo cyborg molto prima che il primo bug si insinuasse nella prima valvola termoionica (tubo a vuoto) del primo computer mainframe (sistema centrale).
L’uomo delle caverne che brandiva una lancia e accendeva un fuoco era il cyborg originale. Galileo che guardava il cielo con il suo telescopio era sia un uomo del Rinascimento che un cyborg. Quando ti metti le lenti a contatto la mattina, sei un cyborg.
Nel corso della nostra storia come specie, la tecnologia ha potenziato i nostri sensi. Ci ha offerto una maggiore padronanza e controllo sia della nostra vita che del mondo che ci circonda. Allo stesso modo, la tecnologia è stata usata per opprimerci e sfruttarci – come testimonierà senza difficoltà chiunque abbia mai fissato la canna del fucile del suo oppressore.
“La tecnologia”, secondo la prima legge della tecnologia di Melvin Kranzberg, “non è né buona né cattiva, né neutrale”.
Allora cosa stabilisce se la tecnologia contribuisce al nostro benessere, ai diritti umani e alla democrazia o se li corrode? Cosa separa la buona tecnologia dalla cattiva tecnologia? E, visto che ci siamo, cosa separa il telescopio di Galileo e le tue lenti a contatto da Google e Facebook? E perché è importante se ci vediamo come cyborg o no?
Noi tutti dobbiamo cercare di capire le risposte a queste domande. Il non farlo potrebbe avere un prezzo davvero molto alto. Queste non sono semplicemente domande sulla tecnologia. Sono domande che vanno al cuore di ciò che significa essere umani nell’era digitale e della rete. Il modo in cui scegliamo di rispondere a queste domande ha conseguenze fondamentali per il nostro benessere, sia a livello personale che come società. Le risposte che scegliamo determineranno il carattere delle nostre società e, nel lungo termine, forse anche la sopravvivenza della nostra specie.
Proprietà e controllo del sé nell’era digitale e della rete
Immagina un mondo in cui alla nascita ti viene assegnato un dispositivo che da quel momento in poi ti guarda, ascolta e ti segue. Può anche leggere la tua mente.
Nel corso degli anni, questo dispositivo registra ogni tuo pensiero, ogni parola, ogni movimento e ogni interazione. Invia tutte queste informazioni su di te a un potente computer centrale di proprietà di una società multinazionale. Lì, questi aspetti del tuo io sono messi insieme usando algoritmi per creare una tua simulazione. La società multinazionale usa la tua simulazione come un doppio digitale per manipolare il tuo comportamento.
Il tuo doppio digitale ha un valore inestimabile. È tutto ciò che ti rende quello che sei (a parte il tuo corpo fisico). La società multinazionale capisce che non ha bisogno di possedere il tuo corpo fisico per possederti. Coloro che si oppongono lo chiamano il sistema di Schiavitù 2.0.
Per tutto il giorno la società multinazionale sottopone la tua simulazione a dei test. Cosa ti piace? Cosa ti rende felice? Cosa ti rende triste? Cosa ti fa paura? Chi ami? Cosa farai questo pomeriggio? Usa le informazioni che ricava da questi test per farti fare quello che vuole. Magari per comprare un vestito nuovo o votare per un certo politico.
La società multinazionale è politica. Deve continuare a sopravvivere, crescere e prosperare. Non può essere ostacolata dai regolamenti. Quindi deve influenzare il discorso politico. Per fortuna, a tutti coloro che oggi sono dei politici è stato assegnato lo stesso dispositivo che ti è stato assegnato alla nascita. Quindi la società multinazionale possiede anche i loro doppi digitali. Questo rende molto più facile per la società multinazionale soddisfare i propri desideri.
Detto questo, la società multinazionale non è onnisciente. Per esempio, potrebbe arrivare alla conclusione per errore – basandosi sui tuoi pensieri, parole e azioni – che sei un terrorista anche se non lo sei. Quando la società multinazionale ha ragione, il tuo doppio digitale è uno strumento inestimabile per manipolare il tuo comportamento. Quando si sbaglia, potrebbe mandarti in prigione. In ogni caso, perdi.
Sembra una distopia fantascientifica cyberpunk, vero?
Sostituisci “la società multinazionale” con “Silicon Valley”. Sostituisci il potente computer centrale con ‘The Cloud’. Sostituisci “il dispositivo” con “il tuo smartphone e il tuo assistente domestico smart e la tua smart city e la tua smart questo, quello e altro”.
Benvenuti sulla Terra, circa ai giorni nostri.
Capitalismo della sorveglianza
Viviamo in un mondo in cui una manciata di società multinazionali ha accesso a un flusso illimitato e costante ai dettagli più intimi delle nostre vite. I loro dispositivi ci guardano, ascoltano e ci rintracciano, nelle nostre case, su Internet e (sempre di più) sui marciapiedi e nelle strade. Questi non sono strumenti che ci appartengono e controlliamo. Sono gli occhi e le orecchie del sistema socio-tecnologico-economico che Shoshana Zuboff ha chiamato “capitalismo della sorveglianza”.
Proprio come nel nostro incubo cyberpunk, i baroni ladri della Silicon Valley non si accontentano di guardare e ascltare. Per esempio, alla sua conferenza degli sviluppatori del 2017, Facebook ha annunciato che sessanta ingegneri stavano già lavorando al progetto per leggere – letteralmente – la tua mente 1.
Sopra ho posto la questione di cosa distingue il telescopio di Galileo e le lenti a contatto dalle offerte di merci di Facebook, Google e altri capitalisti della sorveglianza.
Comprendere la risposta a questa domanda è cruciale per capire fino a che punto il concetto stesso di individualità sia minacciato dal capitalismo della sorveglianza.
Quando Galileo usava il suo telescopio, solo lui vedeva ciò che guardava e solo lui sapeva cosa stava guardando. Lo stesso vale per le lenti a contatto. Se Galileo avesse comprato il suo telescopio da Facebook, Facebook, Inc. avrebbe registrato tutto quello che ha guardato. Allo stesso modo, se compri le lenti a contatto da Google, avranno telecamere integrate e Alphabet, Inc. vedrà tutto quello che stai vedendo. (Google non produce ancora queste lenti, ma hanno un brevetto 2. Per il momento, se non puoi aspettare, Snapchat fa degli occhiali con telecamere al loro interno).
Quando usi una matita per scrivere nel tuo diario, né la matita né il tuo diario sanno cosa hai scritto. Quando scrivi i tuoi pensieri in un documento di Google, Google conosce ogni parola.
Quando mandi una lettera a un amico per posta ordinaria, l’ufficio postale non sa cosa hai scritto. Se chiunque altro apre la tua busta è un crimine . Quando mandi un messaggio istantaneo a un amico su Facebook Messenger, Facebook legge ogni parola.
Quando accedi a Google Play Services su un telefono Android, ogni tua mossa e interazione viene meticolosamente registrata, inviata a Google, memorizzata per sempre, analizzata e usata contro di te nel tribunale del capitalismo della sorveglianza.
Una volta eravamo noi a leggere i giornali. Oggi, i giornali ci leggono. Mentre guardi YouTube, anche YouTube ti guarda.
Sono sicuro che capisci di cosa si tratta.
Finché noi (come persone) non possediamo e controlliamo la nostra tecnologia, “smart” non è altro che un eufemismo per “sorveglianza”. Un telefono intelligente è un dispositivo di tracciamento, una casa intelligente è una cella da interrogatorio, e una città intelligente è un panopticon.
Google, Facebook e altri capitalisti della sorveglianza sono fabbriche intensive di esseri umani. Fanno i loro miliardi allevandoti per i tuoi dati e si servono di quella conoscenza intima della tua vita per manipolare il tuo comportamento.
Queste organizzazioni scansionano costantemente l’umanità. Esistono per digitalizzarti, per possedere quel doppio digitale e per usarlo come doppio per diventare ancora più grandi e potenti.
Dobbiamo capire che queste società multinazionali non sono anomalie. Sono la norma. Sono il mainstream. Il mainstream della tecnologia oggi è una fuoriuscita tossica di capitalismo clientelare americano che minaccia di inghiottire l’intero pianeta. Noi, qui in Europa, non siamo certo immuni ai suoi fumi tossici.
I nostri politici vengono affascinati facilmente dai milioni che queste società multinazionali e spendono nelle lobby di Bruxelles. Sono incantati dalla saggezza della Singularity University (non è un’università). Nel frattempo, le nostre scuole accumulano i Chromebook per i nostri figli. Le nostre tasse vengono abbassate, in modo che i capitalisti della sorveglianza non siano eccessivamente gravati nel caso volessero ordinare un’altra Guinness. E i nostri politici istituzionalmente-corrotti sono troppo occupati a organizzare conferenze sulla protezione dei dati tenute da Google e Facebook per proteggere i nostri interessi. Lo so, perché ho parlato a una l’anno scorso. L’oratore di Facebook era appena uscito dal suo lavoro all’ufficio francese per la protezione dei dati, rinomato per la bellezza e l’efficienza delle sue porte girevoli.
Qualcosa deve cambiare.
E sono sempre più convinto che se questo cambiamento arriverà, deve venire dall’Europa.
La Silicon Valley non risolverà il problema che essa stessa ha creato. Soprattutto perché società multinazionali come Google e Facebook non vedono i miliardi di profitto come un problema. Il capitalismo della sorveglianza, secondo i suoi propri criteri di successo, non è affatto problematico. Funzionano meravigliosamente per società multinazionali come Google e Facebook. Studiano i loro bilanci sorridendo, e ridono in faccia agli enti di controllo le cui multe ridicole superano a malapena un paio di giorni di entrate.
È stato detto che “punibile con una multa” significa “legale per i ricchi” 3. Questo è vero due volte quando si tratta di regolamentare multinazionali da mille miliardi di dollari.
Allo stesso modo, il Venture Capital (capitale di rischio) non investirà in soluzioni che distruggerebbero il modello di business immensamente lucrativo e che ha contribuito a finanziare.
Quindi, quando vedi iniziative come il cosiddetto Centre for Humane Technology con investitori di Venture Capital ex dipendenti di Google, fatti qualche domanda. E magari risparmiane qualcuna per le organizzazioni che pretendono di creare alternative etiche mentre nel frattempo sono finanziate dai capitalisti della sorveglianza. Mozilla, per esempio, prende centinaia di milioni di dollari da Google ogni anno 4. Da loro ha preso più di un miliardo di dollari in totale. Sei felice di affidare a loro lo sviluppo di alternative etiche?
Se vogliamo tracciare un percorso diverso in Europa, dobbiamo finanziare e costruire la tecnologia in modo diverso. Dobbiamo avere il coraggio di andare in una direzione diversa da quella dei nostri amici d’oltreoceano. Dobbiamo avere consapevolezza di noi stessi e dire alla Silicon Valley e ai suoi lobbisti che non compriamo quello che ci offrono.
E dobbiamo fondare tutto questo su una solida base di leggi sui diritti umani. Ho detto “diritti umani”? Volevo dire diritti dei cyborg.
I diritti dei cyborg sono diritti umani
Siamo di fronte a una crisi dei diritti umani che è profonda e che ci rimanda a ciò che intendiamo per “umano”.
Tradizionalmente, delimitiamo il nostro sé all’interno dei confini biologici. Inoltre, abbiamo un sistema di leggi e sentenze che mira a proteggere l’integrità di quei confini e quindi la dignità del sé. Chiamiamo questo sistema legge sui diritti umani.
Purtroppo, questa definizione del sé non è più adeguata a proteggerci completamente nell’era digitale e della rete.
In questa nuova era, espandiamo le nostre capacità biologiche usando tecnologie digitali e di rete. Estendiamo le nostre menti e noi stessi utilizzando la tecnologia moderna. Pertanto, dobbiamo ampliare la nostra comprensione dei confini del sé per includere le tecnologie con cui estendiamo noi stessi. Estendendo la definizione di sé, possiamo assicurarci che la legge sui diritti umani comprenda e quindi protegga la totalità del sé nell’era digitale e della rete.
Come cyborg, siamo esseri frammentati. Parti di noi vivono sui nostri telefoni, parti su un server da qualche parte, parti su un portatile. L’integrità del sé nell’era digitale e della rete è la somma totale dell’integrità di questi frammenti.
Quindi i diritti dei cyborg sono diritti umani applicati all’io cyborg. Ciò di cui non abbiamo bisogno è un insieme separato di “diritti digitali” – probabilmente molto ridotti – . Questo è il motivo per cui la Dichiarazione Universale dei Diritti dei Cyborg 5 non è un documento a sé stante, ma un addendum alla Dichiarazione Universale dei Diritti Umani.
Mentre la tutela dei diritti costituzionali dei cyborg sia inevitabilmente un obiettivo a lungo termine, noi non dovremmo attendere una legge costituzionale prima di agire. Possiamo e dobbiamo iniziare a proteggerci creando alternative etiche alla tecnologia tradizionale.
Tecnologia etica
Una tecnologia etica 6 è uno strumento che possiedi e controlli. È uno strumento progettato per rendere la tua vita più gradevole e semplice. È uno strumento che migliora la tua capacità e migliora la tua vita. È uno strumento che agisce solo per – e mai contro – i tuoi interessi.
Al contrario, una tecnologia non etica è uno strumento di proprietà e controllato da società e governi. Agevola i loro interessi a spese dei tuoi. È una trappola scintillante progettata per catturare la tua attenzione, assuefarti, tracciare ogni tua mossa e profilarti. È una fabbrica intensiva travestita da parco giochi.
La tecnologia non etica è tossica per i nostri diritti umani, il benessere e la democrazia.
Piantare semi migliori
La tecnologia etica non cresce sugli alberi: bisogna finanziarla. Il modo in cui la si finanzia è importante.
La tecnologia non etica è finanziata dal Venture Capital. Il Venture Capital non investe in una società, investe nella vendita della società. Investe anche in società molto rischiose. Un venture capitalist nella Silicon Valley investirà, diciamo, 5 milioni di dollari in 10 diverse startup, sapendo che 9 di esse falliranno. Così lui (di solito è un lui), ha bisogno che la decima sia un unicorn da un miliardo di dollari in modo da poter recuperare da cinque a dieci volte i suoi soldi. (Non sono nemmeno i suoi soldi, appartengono ai suoi clienti). L’unico modello di business che conosciamo nella tecnologia che fornisce quel tipo di crescita è l’allevamento delle persone. La schiavitù pagava bene. Anche la schiavitù 2.0 paga bene.
Non dovremmo sorprenderci che un sistema che valorizza più di ogni altra cosa la crescita simile al cancro abbia prodotto tumori come Google e Facebook. Quello che è stupefacente è che sembra celebriamo i tumori invece di curare il paziente. E ancora più sconcertante è che qui in Europa sembriamo ostinatamente determinati a infettarci con la stessa malattia.
Non facciamolo.
Finanziamo alternative etiche.
Dai beni comuni.
Per il bene comune.
Sì, questo significa con le nostre tasse. È un po’ quello a cui servono (costruire infrastrutture condivise per il bene comune che faccia avanzare il benessere della nostra gente e delle nostre società). Se la parola “tasse” ti spaventa o suona troppo antiquata, sostituiscila semplicemente con “crowdfunding obbligatorio” o “filantropia democratizzata”.
Finanziare la tecnologia etica dai beni comuni non significa che facciamo sviluppare, possedere o controllare le nostre tecnologie dai governi. Né significa che nazionalizziamo società multinazionali come Google e Facebook. Smantellatele! Certo. Regolamentarle! Certo. Fare qualsiasi cosa che limiti il più possibile i loro abusi. Ma l’unica cosa peggiore di un panopticon aziendale è un panopticon statale (non che queste due cose si escludano a vicenda).
Non sostituiamo un grande fratello con un altro.
Investiamo invece in molte piccole organizzazioni indipendenti senza scopo di lucro e incarichiamole di costruire le alternative etiche. Facciamole competere tra loro mentre lo fanno. Prendiamo ciò che sappiamo funziona dalla Silicon Valley (piccole organizzazioni che lavorano in modo iterativo, competono e falliscono velocemente) e rimuoviamo ciò che è tossico: il Venture Capital, il feticismo della crescita e i ritiri dettati dal profitto.
Invece di startup, costruiamo stayup in Europa.
Invece di imprese usa e getta che o falliscono velocemente o diventano tumori maligni, finanziamo organizzazioni che o falliscono velocemente o diventano fornitori sostenibili di bene sociale.
Quando ho menzionato questo piano diversi anni fa al Parlamento europeo, le mie parole sono cadute nel vuoto. Non è ancora troppo tardi per provare. Ma ogni giorno che rimandiamo, il capitalismo della sorveglianza si radica sempre più nel tessuto delle nostre vite.
Dobbiamo superare questo fallimento dell’immaginazione e basare la nostra infrastruttura tecnologica su quei principi che sono il meglio dell’umanità: diritti umani, giustizia sociale e democrazia.
Oggi, l’UE agisce come un dipartimento di ricerca e sviluppo non retribuito della Silicon Valley. Finanziamo le startup che, se hanno successo, vengono vendute alle società multinazionali della Silicon Valley. Se falliscono, il contribuente europeo paga il conto. Questa è una follia.
La CE deve smettere di finanziare le startup e investire invece nelle stayup. Investire 5 milioni di euro in dieci stayup in ogni area in cui vogliamo alternative etiche. A differenza di una startup, quando le stayup hanno successo, non scompaiono nella proprietà dei profittatori. Non possono essere comprate da Google o Facebook. Rimangono delle no-profit europee sostenibili che lavorano per fornire tecnologia come bene sociale.
Inoltre, il finanziamento di una stayup deve essere accompagnato da una rigorosa specificazione del carattere della tecnologia che costruirà. I beni costruiti con fondi pubblici devono essere beni pubblici. La Free Software Foundation Europe sta attualmente sensibilizzando in questo senso con la loro campagna „public money, public code“/“denaro pubblico, codice pubblico”. Tuttavia dobbiamo andare oltre il principio dell’”open source” per stabilire che la tecnologia sviluppata dalle stayup non solo deve essere pubblica, ma anche non può essere limitata nella sua distribuzione.
Per il software e l’hardware, questo significa usare licenze copyleft. Una licenza copyleft assicura che chi usa la tecnologia pubblica deve condividere allo stesso modo. Le licenze share-alike, che implicano una condivisione generale, sono essenziali affinché i nostri sforzi non diventino un eufemismo della privatizzazione e per evitare una catastrofe dei beni comuni. Le società con grande disponibilità finanziaria non devono essere messe in grado di prendere ciò che creiamo con fondi pubblici, investirci sopra i loro milioni, e non condividere il valore aggiunto.
Infine, dobbiamo stabilire che le tecnologie svillupate da stayup sono peer to peer. I tuoi dati devono rimanere sui dispositivi che possiedi e controlli. E quando comunichi, devi comunicare direttamente (senza un intermediario “man in the middle” come Google o Facebook). Laddove ciò sia assolutamente impossibile tecnicamente, tutti i dati privati controllati da una terza parte (per esempio un web host) devono essere crittati end-to-end e tu avere avere l’unica chiave.
Anche senza investimenti statisticamente rilevanti in tecnologia etica, ci sono già piccoli gruppi che lavorano su alternative. Mastodon 7, un’alternativa etica, federata, a Twitter, è stata creata da una persona sui vent’anni. Un paio di persone si sono riunite per creare un progetto chiamato Dat 8 che potrebbe essere alla base di un web decentralizzato. Da oltre dieci anni, dei volontari gestiscono un sistema alternativo non commerciale di nomi di dominio chiamato OpenNIC 9 che potrebbe dare a tutti il proprio posto sul web…
Anche se senza alcun supporto questi semi stanno iniziando a germogliare, immagina cosa potremmo ottenere se iniziassimo davvero ad annaffiarli e a piantarne di nuovi. Investendo in stayup, possiamo iniziare un cambiamento fondamentale verso la tecnologia etica in Europa. Possiamo iniziare a costruire un ponte da dove siamo a dove vogliamo essere. Da un mondo in cui le società multinazionali ci possiedono attraverso i nostri doppi a un mondo in cui noi siamo noi stessi. Da un mondo in cui stiamo diventando di nuovo proprietà di altri a un mondo in cui rimaniamo come persone. Da un capitalismo della sorveglianza a una peerocrazia.
NOTE
1. Facebook has 60 people working on how to read your mind (The Guardian)
2. After Google Glass, Google developing contact lens camera (c|net) (c|net) ↩︎
3. theconcealedweapon.tumblr.com ↩︎
4. Mozilla terminates its deal with Yahoo and makes Google the default in Firefox again (Techcrunch) ↩︎
5. Universal Declaration of Cyborg Rights ↩︎
6. Ethical Design Manifesto ↩︎
7. Join Mastodon ↩︎
8. Dat project ↩︎
9. OpenNIC ↩︎
++-__-++